AI Routing technology
What is LLM Router?

Date
Author
Andrew Zheng
Large Language Models (LLMs) have become the backbone of modern AI applications, powering everything from chatbots and virtual assistants to research tools and enterprise solutions. However, not all LLMs are created equal—each has unique strengths, limitations, and cost factors. Some excel at reasoning, while others are better at creative writing, coding, or handling structured queries. This is where an LLM Router comes in.
An LLM Router acts like an intelligent traffic controller, automatically directing user prompts to the most suitable model based on the task at hand. Instead of relying on a single model, businesses and developers can optimize performance, accuracy, and costs by routing queries to the right LLM in real time. As AI adoption grows, LLM routing is becoming an essential layer for building scalable, reliable, and efficient AI systems.
What Is an LLM Router?
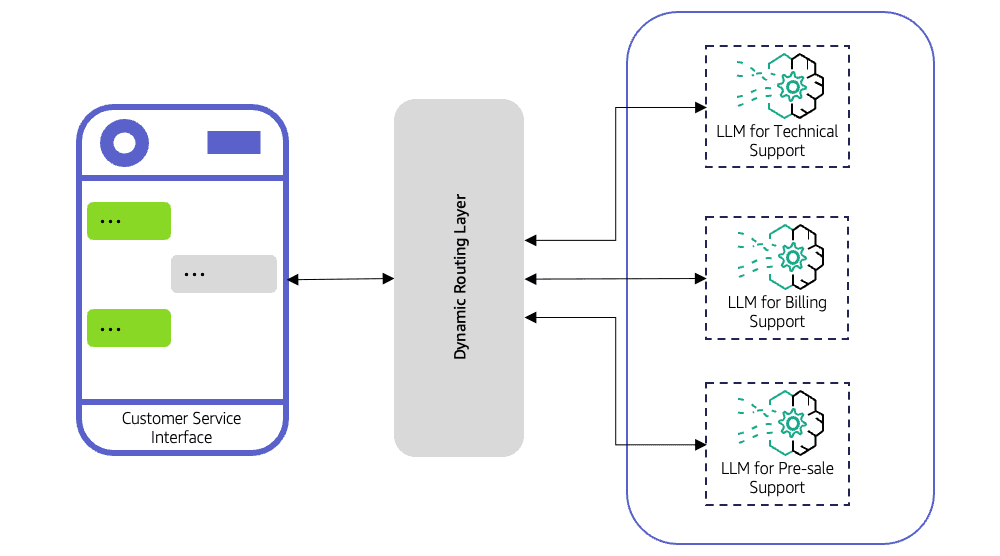
An LLM Router decides which Large Language Model should handle each request. Instead of sending every query to a single model, it evaluates the input, applies routing logic, and forwards it to the most suitable model.
The router can follow simple rules, such as directing code-related queries to a programming-focused model, or use advanced strategies like classifiers, embeddings, or lightweight predictive models to determine which LLM will deliver the best response.
How It Works?
Input: The router receives the user’s query.
Analyze: It inspects the query, checking metadata, tags, type, complexity, or even intent and sentiment. This helps it understand the exact requirements of the request.
Select Model: The router chooses the most appropriate LLM based on factors such as domain expertise, accuracy, latency, or cost.
Fallback Mechanism: If the selected model fails, times out, or produces a low-confidence answer, the router automatically redirects the request to a backup model to maintain reliability.
This approach eliminates the “one-size-fits-all” problem. Lightweight models handle routine queries efficiently, while complex or reasoning-heavy tasks go to more capable LLMs.
Practically, the router sits between applications and multiple LLMs, optimizing performance, reducing costs, and minimizing dependence on any single provider. This setup ensures that every request reaches the right model while keeping AI systems reliable and flexible.
Why Do We Need an LLM Router?
Companies increasingly rely on Large Language Models for tasks ranging from chatbots and virtual assistants to content creation and data analysis.
Using a single LLM for all tasks, however, creates challenges. Some models respond quickly but lack depth, while others provide accurate results at high latency and cost. Without a way to manage these differences, teams constantly trade off performance, accuracy, and budget.
An LLM Router solves this by intelligently directing requests to the model best suited for the task.
Consider This Scenario
A customer support system receives two types of queries.
A simple request like “What are your working hours?” doesn’t need a highly advanced model, while a complex technical question about product troubleshooting does. Without an LLM Router, all queries might go to a high-powered, expensive model. This increases cost and slows down response times. With a router, the simple query goes to a fast, lightweight model, while the complex one is routed to a more capable LLM, optimizing speed, cost, and accuracy.
Benefits for Companies
Optimized Performance: Matches query complexity with the right model.
Cost Efficiency: Avoids overusing expensive models for routine tasks.
Reliability: Fallback mechanisms ensure consistent responses even if a model fails.
Flexibility: Mix models from different providers to avoid vendor lock-in.
Scalability: Efficiently manages growing query volumes and load distribution.
By intelligently routing queries, companies deliver faster, more accurate, and cost-effective AI services. LLM Routers transform AI deployment from a one-size-fits-all approach into a flexible, reliable, and efficient system, making them essential for modern AI infrastructure.
Key Functions of an LLM Router
An LLM Router is more than a traffic director, it provides several core functions that make AI systems smarter, faster, and more reliable. Understanding these functions helps organizations design AI workflows that scale efficiently while maintaining quality.
Request Analysis
Before any routing happens, the router analyzes incoming queries. It examines metadata, tags, query type, complexity, and sometimes intent or sentiment. This analysis provides context so the router can decide which model is best suited to handle the request. For example, a customer question about billing can be routed to a lightweight general-purpose LLM, while a technical troubleshooting query is sent to a domain-specific model.
Model Selection
The router selects the most appropriate model based on multiple criteria, including:
Domain Expertise: Some LLMs are trained for specific industries or topics.
Accuracy Needs: Critical tasks may require models with higher reasoning capabilities.
Latency and Speed: Quick responses can use lighter models.
Cost Efficiency: Expensive models are reserved for high-value queries.
By considering these factors, the router ensures each request gets the best balance of speed, accuracy, and cost.
Load Balancing
When multiple models can handle the same task, the router distributes requests intelligently to avoid overloading any single model. This improves overall system responsiveness and ensures consistent performance during peak usage.
Fallback and Error Handling
Even the best models can fail, time out, or return low-confidence responses. The router implements fallback mechanisms, automatically rerouting queries to backup models. This ensures continuity and reliability without user disruption.
Monitoring and Analytics
Advanced routers track usage patterns, model performance, and query outcomes. These insights help teams optimize routing strategies, select better models, and reduce costs over time.
An LLM Router acts as the decision-making hub of multi-model AI systems. By analyzing requests, selecting the right model, balancing load, handling failures, and providing insights, it ensures that every query is processed efficiently, accurately, and reliably. This combination of functions makes LLM Routers a critical component in building robust, scalable, and cost-effective AI solutions.
Types of Routing Strategies in LLM Routers
LLM routers use different strategies to direct queries to the most suitable language model efficiently. These strategies generally fall into three categories: static, dynamic, and hybrid, with advanced systems sometimes incorporating reinforcement learning.
Static Routing
Static routing relies on predefined rules to decide which model handles a query. It ensures consistent routing behavior and is easy to implement.
Rule-Based Routing: Sends queries to models based on specific conditions such as keywords, metadata, or tags.
Hashing Techniques: Distributes queries evenly across models using consistent hashing, maintaining load balance even when models are added or removed.
Dynamic Routing
Dynamic routing adapts in real-time, selecting models based on current system performance and query context.
Latency-Based Routing: Chooses the model with the fastest response time to meet real-time requirements.
Cost-Aware Routing: Sends queries to models that offer the best performance-to-cost ratio, optimizing resource usage.
Load-Aware Routing: Monitors current model load to prevent bottlenecks and ensure smooth performance.
Hybrid Routing
Hybrid strategies combine static and dynamic approaches for greater flexibility and efficiency.
Contextual Routing: Analyzes query context to apply dynamic routing within predefined static rules.
Role-Aware Routing: In multi-agent systems, routes queries based on the agent’s role or task stage, improving collaboration and resource use.
Reinforcement Learning-Based Routing
Some advanced systems use reinforcement learning to continuously improve routing decisions. These routers learn from past queries and model performance, optimizing routing over time for complex or evolving workloads.
Why Use an LLM Router?
A single-model approach is often rigid and expensive. Here is how an LLM Router transforms your AI infrastructure:
Benefit | How it Works | The Impact |
Optimized Performance | Routes complex tasks to 80B+ models and simple tasks to 3B-8B models. | Faster response times without sacrificing accuracy. |
Cost Efficiency | Reserves expensive models (like GPT-4) only for high-value queries. | Up to 45% reduction in operational compute costs. |
Bulletproof Reliability | Automatically triggers fallbacks if a model fails or times out. | Zero downtime and consistent user experience. |
Vendor Flexibility | Mix and match models from Infron, Clarifai, or Hyperbolic. | No vendor lock-in; switch models as new tech emerges. |
Dynamic Scalability | Distributes high-volume traffic intelligently across multiple endpoints. | Prevents system bottlenecks during peak usage. |
Common Use Cases for LLM Routers
LLM Routers are increasingly used across enterprises to optimize AI performance, reliability, and efficiency. They enable intelligent query routing, ensuring the right model handles each task based on complexity, domain, and context.
Customer Support Automation
Enterprises handle thousands of customer queries daily, from simple FAQs to complex technical issues. LLM Routers direct routine questions to fast, lightweight models while routing complicated issues to more capable models. This ensures fast, accurate, and consistent responses, improving customer satisfaction and reducing operational strain.
Knowledge Management and Enterprise Search
Companies maintain large repositories of internal documents, manuals, and policies. Routers analyze queries and route them to models optimized for reasoning, summarization, or domain-specific knowledge. Employees receive precise, contextually relevant information without overloading high-cost models.
Workflow and Task Automation
LLMs are widely used for report generation, data analysis, and decision-support tasks. Routers dynamically assign high-complexity queries to powerful models and routine tasks to lighter models, balancing speed, accuracy, and compute costs across enterprise workflows.
Multi-Model Orchestration
Organizations often deploy multiple LLMs across providers or domains. Routers manage model selection, load balancing, and fallback mechanisms, ensuring reliability, flexibility, and scalability in large-scale AI systems.
Product Recommendations and Personalization
For E-commerce or SaaS platforms, LLM Routers can assign personalization tasks to models trained on user behavior and context while delegating generic recommendations to simpler models. This improves recommendation accuracy and performance while controlling costs.
Compliance and Risk Analysis
In finance, legal, or healthcare enterprises, queries may require strict adherence to regulations or domain-specific guidelines. Routers can direct sensitive or high-stakes queries to models with domain expertise, ensuring compliance while general tasks are handled by standard models.
Content Generation and Summarization
For marketing, knowledge sharing, or documentation, LLM Routers can allocate complex content creation tasks to high-quality models and simpler summarization or drafting tasks to faster models, optimizing efficiency without compromising output quality.
By applying LLM Routers across these diverse scenarios, enterprises can scale AI intelligently, maintaining performance, reliability, and cost-effectiveness across multiple workflows and applications.
LLM Router vs LLM Gateway
After exploring how LLM Routers power a wide range of enterprise applications, it’s important to understand how they differ from another key component in multi-model AI systems.
An LLM Router is focused on intelligent request routing. Its primary function is to analyze incoming queries, evaluate context, complexity, and metadata, and then direct each request to the most suitable model. Routers often incorporate advanced strategies such as dynamic routing, context-aware decision-making, and fallback mechanisms to optimize for accuracy, speed, and cost.
They are particularly critical in environments where queries vary widely in type, domain, or computational requirements, allowing enterprises to balance load and maintain high performance.
An LLM Gateway, on the other hand, acts as a centralized access point for interacting with one or multiple LLMs. Its primary role is to simplify integration, provide standardized APIs, manage authentication, handle rate-limiting, and monitor usage.
Unlike routers, gateways do not typically make intelligent model-selection decisions; they provide uniform access and operational controls to facilitate multi-model deployments. Gateways focus more on infrastructure-level management, security, and scalability rather than query-level optimization.
Key Differences
Feature | LLM Router | LLM Gateway |
|---|---|---|
Primary function | Intelligent routing of queries | Centralized access and management |
Decision-making | Analyzes context, complexity, metadata | Minimal or none; routes all requests uniformly |
Performance optimization | Yes – balances speed, accuracy, and cost | No – focuses on access, not query selection |
Fallback mechanism | Yes – redirects failed or low-confidence queries | No – typically passes queries as-is |
Use case | Multi-model deployment with dynamic query requirements | Multi-model or single-model API access, security, and monitoring |
Routers and gateways often work together in layered architectures. The gateway provides a secure, standardized entry point for applications, while the router sits behind it, making intelligent model selection decisions. This combination allows enterprises to achieve both operational control and optimized query handling.
Understanding the distinction between LLM Routers and LLM Gateways helps organizations deploy multi-model AI systems effectively.
Routers drive intelligent, context-aware performance, while gateways ensure secure, scalable, and reliable access, creating a robust foundation for enterprise AI.
Infron LLM Gateway
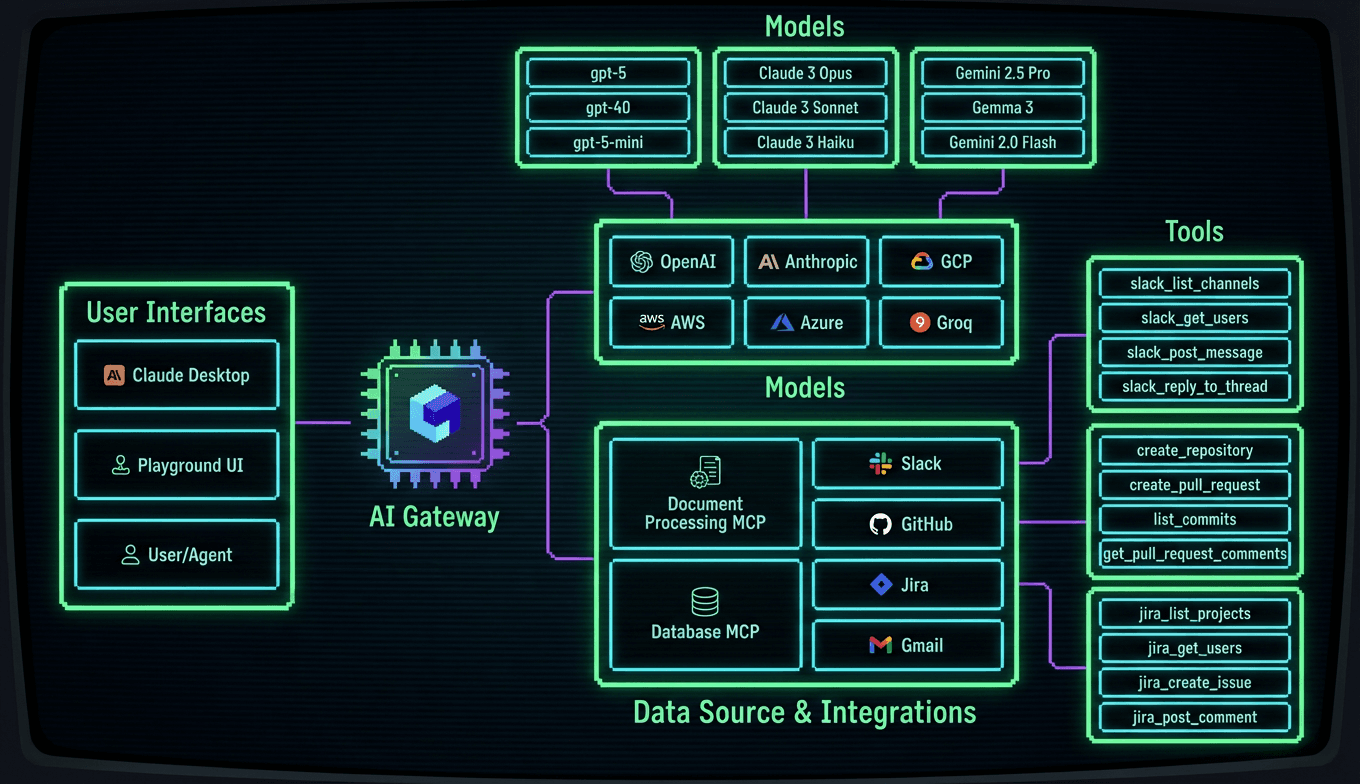
The Infron LLM Gateway is an enterprise-ready platform that unifies access to all major large language models (LLMs) through a single, secure, and high-performance API.
It simplifies GenAI infrastructure by integrating over 150 models and agents, including OpenAI, Anthropic Claude, Gemini, Tavily, JIna and open-source frameworks, without requiring code changes. Teams can use one consistent API for chat, completion, embedding, and reranking workloads while centralizing authentication and API key management.
Key Features:
Unified LLM API Access: Connect to 150+ LLMs through one endpoint, supporting multiple model types with consistent interfaces.
Deep Observability: Monitor token usage, latency, request volume, and errors with centralized logs and rich metadata tagging.
Quota and Access Control: Enforce RBAC, rate limits, and cost-based quotas per user, team, or environment for governance and budget control.
Low-Latency Inference: Achieve sub-100ms internal latency with scalable infrastructure optimized for high-throughput and real-time workloads.
Smart Routing and Fallbacks: Use latency-based and geo-aware routing with automatic model failover to ensure reliability and uptime.
Final Thoughts
As multi-model strategies become the norm, managing AI at scale now requires two critical components: LLM Routers and LLM Gateways.
Think of the Router as the "brain", it analyzes every query in real-time to pick the best model for the job, balancing cost against performance. The Gateway, by contrast, is the "backbone." It provides the secure, standardized infrastructure needed to monitor usage and enforce operational controls.
Together, they form a layered architecture that balances intelligent decision-making with structural reliability. For any organization aiming to deliver fast, cost-effective AI services, mastering this combination is no longer optional—it’s the only way to stay competitive as the model landscape continues to shift.


