Up to 50% cheaper than dedicated provisioned throughput
Infron PayGo Provisioned Throughput: Elastic LLM Capacity

Date
Author
Andrew Zheng
When a generative AI application moves from an exciting proof of concept into full-scale production, engineering and product teams often run headfirst into the same wall: LLM inference costs that are both punishing and unpredictable.
In the lab, success means accurate outputs and clean reasoning. In production, the CFO wants to know the price per million tokens and why the monthly bill swings by 40% every other month. That tension between cost control and performance is one of the hardest unsolved problems in AI infrastructure today.
Traditional AI cloud providers have left teams with an uncomfortable binary choice: pay for flexibility you can't always afford, or commit to capacity you can't always use. Infron's PayGo Provisioned Throughput (PPT) plan is built to dissolve that tradeoff entirely.
Why LLM Inference Cost Gets Out of Control at Scale
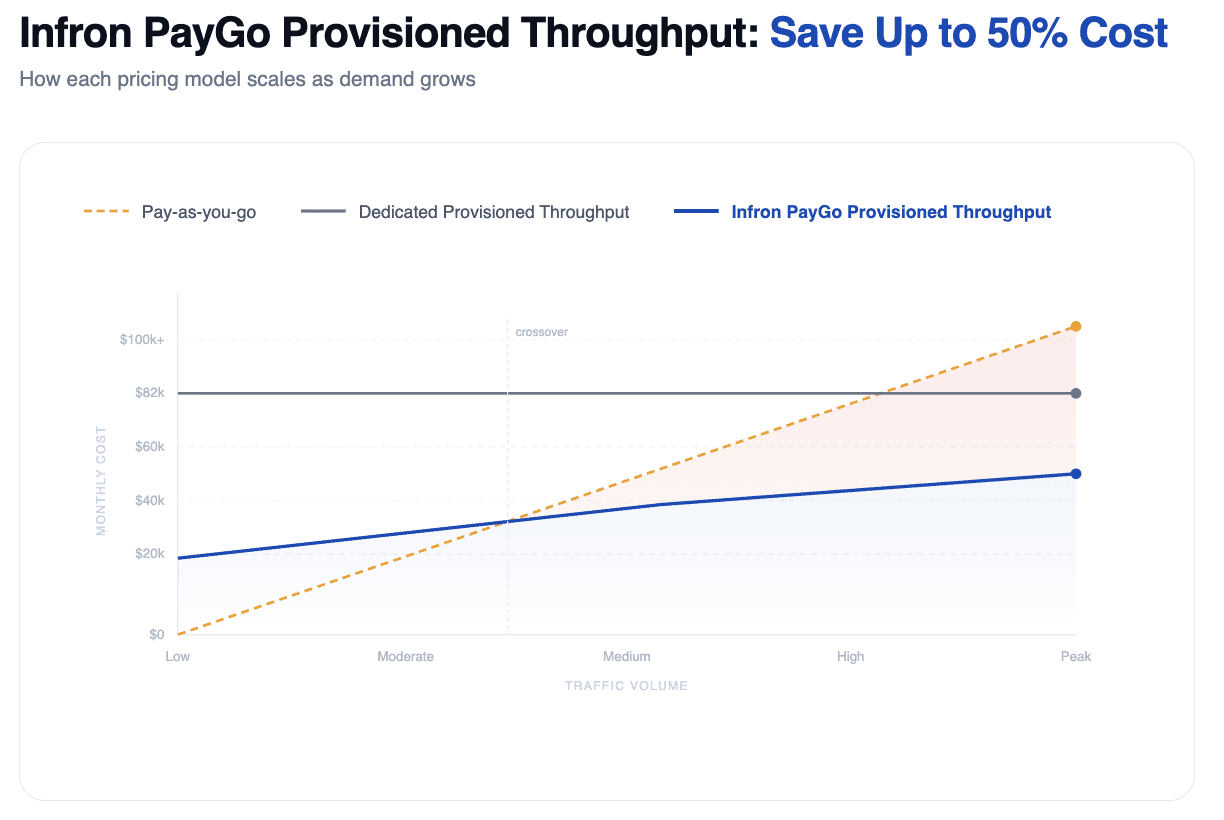
The economics of LLM deployment look manageable at low volume. The moment you move into sustained production traffic, the math changes fast. Two dominant pricing models dominate the market, and both have significant structural flaws for teams operating at scale.
Option 1: Pay-as-you-go — High Flexibility, Higher Bills
Pay-as-you-go works like hailing a cab. You pay only for what you use, with no upfront commitment and maximum flexibility. For early-stage applications with unpredictable or sporadic traffic, it is usually the right call.
The problem surfaces when your application goes from experimental to always-on. A 24/7 customer service bot, a real-time content generation pipeline, a production RAG system handling millions of daily queries — none of these have the kind of "bursty, occasional" usage that pay-as-you-go is priced for. At high volume and consistent throughput, per-token billing accumulates rapidly, and there is no ceiling on how high the monthly bill can climb during traffic spikes or promotional events.
Option 2: Dedicated Provisioned Throughput — Predictable but Wasteful
Dedicated Provisioned Throughput works like owning a car. You commit to a fixed number of model units for a month or longer, gaining guaranteed capacity and predictable billing regardless of whether you fully use it.
The catch is that it demands near-perfect capacity forecasting. Real production workloads rarely cooperate. Traffic is almost always tidal: higher during business hours, lower overnight, different on weekdays versus weekends, volatile during product launches. Dedicated provisioned throughput penalizes that variability in two directions at once.
Overcommit, and you are paying for idle compute during every off-peak hour. Undercommit, and your application hits a capacity ceiling exactly when traffic spikes — the worst possible moment. Long-term contract lock-in compounds the problem further, because the AI model landscape changes faster than most vendor contracts allow teams to respond. A team locked into a six-month agreement on one model family may find themselves unable to switch to a better, cheaper, or more capable model that launches two months in.
Infron PayGo Provisioned Throughput: A New Model for LLM Cost Optimization
Infron's PayGo Provisioned Throughput plan is built on a different premise: teams should not have to choose between cost efficiency and operational flexibility. The PPT plan fuses the economic advantages of reserved capacity with the adaptability of on-demand access, targeting zero waste and zero capacity gaps.
Rather than asking teams to predict their future traffic with perfect accuracy, Infron shifts that responsibility to the platform itself. The system manages resource allocation dynamically based on real load, removing the forecasting burden from engineering and finance teams entirely.
How Infron's PayGo Provisioned Throughput Works
The PPT plan is built on four core mechanisms that work together to keep costs low without sacrificing throughput.
Dynamic Elastic Reservation
Traditional provisioned throughput locks capacity in monthly blocks. Infron's PPT operates on minute-level model unit lifecycle management. The system automatically scales capacity up during peak periods and scales it back down to zero during overnight lows. Teams only pay for capacity that is actively reserved and in use, which means idle overnight compute stops appearing on the invoice entirely.
Baseline + Burst Hybrid Billing
Infron's billing structure uses a layered approach that avoids the all-or-nothing dynamic of conventional pricing models.
Stable baseline traffic is billed at a reserved baseline rate, which is significantly lower than standard pay-as-you-go pricing and provides cost predictability for the core workload. When traffic bursts above the reserved baseline, the overflow automatically shifts to PayGo Provisioned Throughput pricing. Only the excess above the baseline is billed at the burst rate.
This design means teams never get throttled during traffic spikes, and they never overpay to maintain peak capacity around the clock for what might be a few hours of elevated load per week.
Intelligent Scheduling
One of the most operationally significant features of Infron's PPT plan is that it removes the need for manual capacity adjustment. The platform includes an AI-powered scheduling engine that learns each workload's traffic patterns over time — identifying regular peaks, overnight lows, weekly cycles, and seasonal variations.
Based on that learning, the system auto-generates scheduling strategies without requiring any manual intervention. Teams get Serverless-grade simplicity layered on top of enterprise-grade throughput guarantees.
Short-Cycle Rolling Commitments
Because AI model releases now happen on a weekly cadence, long-term vendor lock-in has become a genuine strategic liability. Infron's PPT plan uses rolling short-cycle commitments instead of fixed long-term contracts:
7-day rolling commitment: approximately 15% discount, best suited for teams in rapid iteration or model evaluation phases
30-day rolling commitment: approximately 30% discount, best suited for workloads in stable production with predictable patterns
When a commitment cycle ends, teams can switch to a newer or more cost-effective model immediately, without waiting out a contract.
Pricing Model Comparison
Dimension | Pay-as-you-go | Dedicated Provisioned Throughput | Infron PayGo Provisioned Throughput |
|---|---|---|---|
Flexibility | Very high (no commitment) | Low (long-term lock-in) | High (short rolling cycles) |
Cost predictability | Low (scales linearly with traffic) | High (fixed spend) | Medium-high (fixed baseline + controlled burst) |
Capacity guarantee | None (throttling at peak) | Yes (fixed capacity) | Yes (baseline guaranteed + burst overflow) |
Resource utilization | 100% (pay only for usage) | Low (idle waste at off-peak) | Very high (dynamic scaling) |
Model switching | Instant | Difficult (wait for contract end) | Agile (weekly or monthly cycles) |
Best for | POC, highly variable traffic | Very large and stable workloads | Production tidal traffic, SaaS applications |
LLM Inference Cost in Practice: AI Customer Service Case Study
Consider an e-commerce company running a 24/7 AI customer service system with a predictable tidal traffic pattern: 10 hours of peak load per day requiring 3 model units, and 14 hours of overnight low load requiring only 1 model unit.
Using Pay-as-you-go: Every token across every hour is billed at the standard per-token rate. Daytime peak costs are high, and while overnight costs are lower, the total monthly bill is both expensive and volatile. Any promotional event or traffic spike sends costs unpredictably higher.
Using Dedicated Provisioned Throughput: To protect against daytime peak failures, the team must purchase 3 model units and lock them in for a full month. At $27,379 per unit, that is $82,137 per month — and 2 of those 3 units (roughly 66% of resources) sit idle every night, burning budget without generating value.
Using Infron's PayGo Provisioned Throughput: The system auto-scales to 3 units during peak hours and reduces to 1 unit overnight. The team pays only for what the workload actually demands: 3 units for 10 hours, 1 unit for 14 hours, across 30 days. Compared to Dedicated Provisioned Throughput, the expected savings range from 35% to 50%, while still benefiting from lower per-unit pricing than standard pay-as-you-go. No idle waste. No capacity ceiling. No forecasting required.
Which Plan Is Right for Your AI Infrastructure?
Not every workload is a PPT fit, and the honest answer depends on where your application sits in its lifecycle and how your traffic actually behaves.
Stick with pay-as-you-go if: your application is still in development or testing, traffic is genuinely unpredictable, or your daily call volume is low enough that optimization is not yet a priority.
Consider Dedicated Provisioned Throughput if: your workload is enormous in scale, highly stable with almost no variability, and your traffic volume is large enough that a long-term commitment produces material per-unit savings.
Infron's PayGo Provisioned Throughput is the strongest fit for:
SaaS applications with consistent daily active users and clear workday/off-hours traffic patterns
Content generation platforms that run continuously but see distinct weekday versus weekend usage profiles
Growth-stage companies that are scaling fast, need reliable throughput, but cannot afford to be locked into long-term contracts while the model landscape is still shifting under them
The Next Era of AI Infrastructure Cost Management
Infron's PayGo Provisioned Throughput plan represents more than a new pricing tier. It reflects a broader shift in how AI infrastructure should be designed: not around static resource blocks, but around the actual shape of real workloads.
The conventional approach forced teams to absorb the risk of either overspending or underperforming. Infron moves that risk to the platform level, using intelligent scheduling and dynamic allocation to close the gap between what teams pay and what they actually need.
As generative AI moves from pilot programs into core business infrastructure, the organizations that scale most efficiently will be the ones whose AI cost structures can adapt as quickly as their models do. A billing and routing system that is as intelligent as the models it serves is not a nice-to-have. It is a competitive requirement.
Ready to see how Infron's PayGo Provisioned Throughput plan fits your workload? Visit infron.ai to get started.


