Qwen3-Next-80B-A3B API Provider
Qwen3-Next-80B-A3B API Provider: Choose Smarter for Better AI

Date
Author
Andrew Zheng
Qwen3-Next-80B-A3B is a cutting-edge reasoning model built on the latest Qwen3-Next framework, including Instruct and Thinking variants. It features 80 billion total parameters while activating only 3 billion during inference, delivering high efficiency and powerful performance that competes with significantly larger dense models.
In this article, We deep-dive into Qwen3-Next-80B-A3B, the MoE model delivering flagship performance with only 3B active parameters. This guide compares Infron, Clarifai, and Hyperbolic across performance, architecture, and pricing to help you find the most efficient solution for your AI workflow.
Table Of Contents
What is Qwen3-Next-80B-A3B?
Qwen3-Next-80B-A3B is the first installment in the Qwen3-Next series, delivering state-of-the-art performance in multiple domains.
Basic Information of Qwen3-Next-80B-A3B
Specification | Details |
|---|---|
Parameters | 80B in total with 3B activated |
Architecture | Mixture-of-Experts |
Number of Layers | 48 |
Number of Experts | 512 |
Training Stage | Pretraining (15T tokens) & Post-training |
Context window | 262K natively |
License | Apache 2.0 |
Benchmark and Key Capabilities
Instruct Model Performance
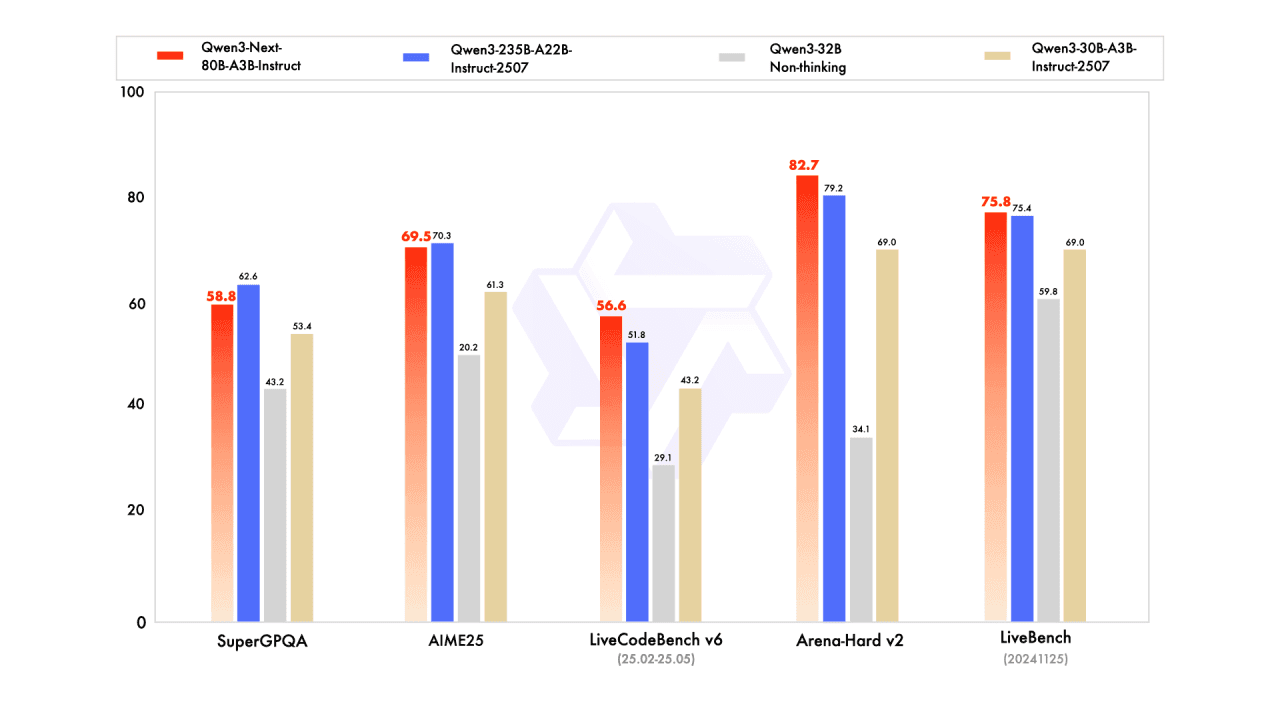
High performance without extreme scale, giving you near-frontier accuracy without paying for 200B+-class models.
Strong general reasoning across math, coding, and mixed benchmarks, making it a reliable default model for broad workloads.
Top performance on Arena-Hard v2, providing strong real-world alignment with human preference tasks.
Cost-efficient upgrade for teams wanting a powerful instruction model without jumping to ultra-large parameter sizes.
Well-balanced across domains, suitable for chat, code assistance, analysis, and evaluation tasks with predictable quality.
Thinking Model Performance
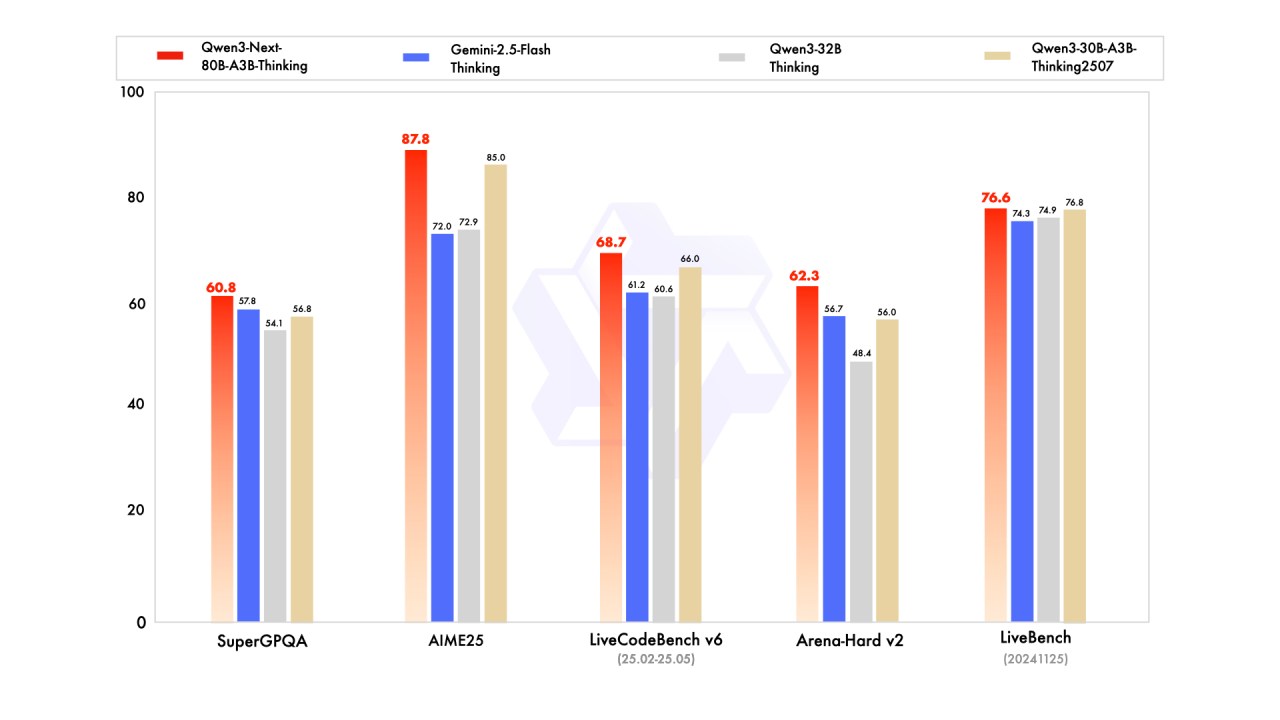
Exceptional deliberate reasoning with standout scores in math (AIME25: 87.8) and long-form logic tasks.
Better chain-of-thought efficiency, letting you achieve deeper reasoning quality while keeping token usage lower than giant models.
Strong alternative to expensive reasoning models, outperforming or matching models like Gemini 2.5 Flash Thinking at a lower parameter scale.
Ideal for decision-making, multi-step problem solving, and scientific workflows, where accuracy and depth matter more than speed.
High performance across coding and evaluation, making it valuable for engineering, research, and enterprise cognitive tasks.
How to Choose the Right API Provider?
Context Length (Higher is better): A larger context length lets the model read and process more text in a single run, supporting deeper summaries, longer conversations, and more complex reasoning.
Token Cost (Lower is better): A lower token cost means each piece of text processed is cheaper, making frequent queries and large scale workloads more budget friendly.
Latency (Lower is better): Lower latency means the model replies faster, creating smoother interactions that are important for assistants, chat tools, and real time systems.
Throughput (Higher is better): Higher throughput means the model can handle more requests at the same time, ensuring stable performance even during heavy usage.
Qwen3-Next-80B-A3B API Provider Comparison
Provider | Context Length | Input/Output Price | Output Speed (Tokens per sec) | Latency | Function Calling | JSON Mode |
Infron | 262K | $0.15/$1.5 per 1M Tokens | 147 | 0.89s | ✅ | ✅ |
Clarifai | 262K | $1.09/$1.08 per 1M Tokens | 175 | 0.32s | ❌ | ❌ |
Hyperbolic | 262K | $0.3/$0.3 per 1M Tokens | 323 | 0.77s | ❌ | ✅ |
Infron delivers the best overall value: the lowest prices, solid speed, and full support for function calling and JSON Mode. It offers the most cost-efficient and developer-friendly option for real production use. Clarifai offers a high token prices and lack of key features make it expensive and less practical for real-world scaling. Hyperbolic provides fast output speed but higher input cost and missing function calling limit its flexibility compared to Infron.
Top Qwen3-Next-80B-A3B API Provider: Infron
Infron provides a simplified API scheme where developers can call AI models right away using an easy-to-use API. By offering affordable, ready-to-use multimodal models like Qwen3-Next-80B-A3B, GLM 4.6, Kimi K2 Thinking, DeepSeek V3.2 Exp, GPT-OSS, and others, it eliminates configuration hassles and lets you begin building without delay.
How to Access via Infron API?
Infron provides a unified API that gives you access to hundreds of AI models through a single endpoint, while automatically handling fallbacks and selecting the most cost-effective options. Get started with just a few lines of code using your preferred SDK or framework.
Step 1: Log In and Access the Model Marketplace
Log in or sign up to your account and click on the Model Marketplace button
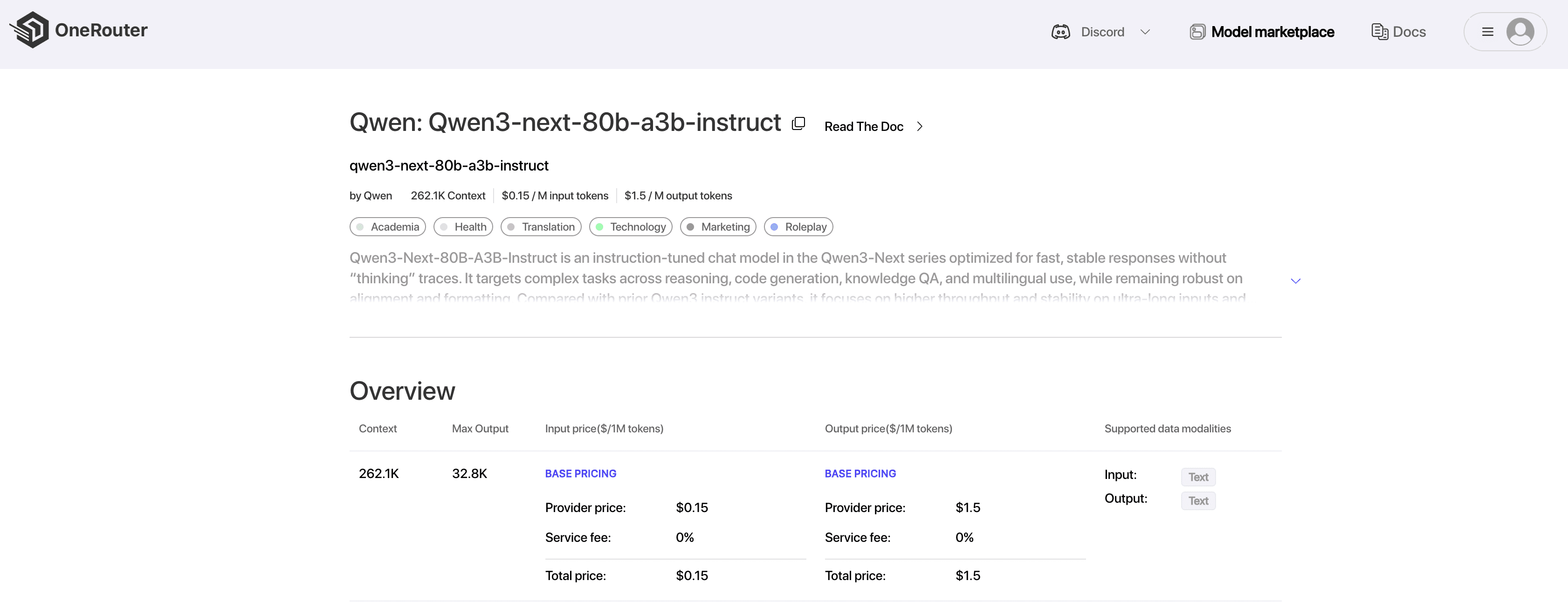
Step 2: Choose Your Model
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get API KEY
To authenticate with the API, Infron provides you with a new API key. Entering the “API Keys“ page, you can copy the API key as indicated in the image.
Step 5: Install the API
Install API using the package manager specific to your programming language.
Once the installation is complete, import the required libraries. Then, initialize the client with your API key to access the Infron LLM. The following snippet shows how Python users can work with the Chat Completions API.
from openai import OpenAI client = OpenAI( base_url="https://llm.onerouter.pro/v1", api_key="<API_KEY>", ) completion = client.chat.completions.create( model="qwen3-next-80b-a3b-instruct", messages=[ { "role": "user", "content": "What is the meaning of life?" } ] ) print(completion.choices[0].message.content)
from openai import OpenAI client = OpenAI( base_url="https://llm.onerouter.pro/v1", api_key="<API_KEY>", ) completion = client.chat.completions.create( model="qwen3-next-80b-a3b-instruct", messages=[ { "role": "user", "content": "What is the meaning of life?" } ] ) print(completion.choices[0].message.content)
Frequently Asked Questions
What is the Qwen3-Next-80B-A3B model?
It is a powerful large language model built on the Qwen3-Next architecture, offering advanced reasoning, strong coding ability, and exceptional performance while keeping inference efficient.
Does Qwen3-Next-80B-A3B support chain-of-thought reasoning?
Yes. The Thinking variant is optimized for multi-step reasoning, problem solving, math, and complex analysis tasks.
Which provider offers the best pricing for Qwen3-Next-80B-A3B?
Infron consistently delivers the lowest input cost and strong performance, making it the most cost-effective option for scaling real workloads. Try [Qwen3-Next-80B-A3B] for Free Now.
Qwen3-Next-80B-A3B is a cutting-edge reasoning model built on the latest Qwen3-Next framework, including Instruct and Thinking variants. It features 80 billion total parameters while activating only 3 billion during inference, delivering high efficiency and powerful performance that competes with significantly larger dense models.
In this article, We deep-dive into Qwen3-Next-80B-A3B, the MoE model delivering flagship performance with only 3B active parameters. This guide compares Infron, Clarifai, and Hyperbolic across performance, architecture, and pricing to help you find the most efficient solution for your AI workflow.
Table Of Contents
What is Qwen3-Next-80B-A3B?
Qwen3-Next-80B-A3B is the first installment in the Qwen3-Next series, delivering state-of-the-art performance in multiple domains.
Basic Information of Qwen3-Next-80B-A3B
Specification | Details |
|---|---|
Parameters | 80B in total with 3B activated |
Architecture | Mixture-of-Experts |
Number of Layers | 48 |
Number of Experts | 512 |
Training Stage | Pretraining (15T tokens) & Post-training |
Context window | 262K natively |
License | Apache 2.0 |
Benchmark and Key Capabilities
Instruct Model Performance
High performance without extreme scale, giving you near-frontier accuracy without paying for 200B+-class models.
Strong general reasoning across math, coding, and mixed benchmarks, making it a reliable default model for broad workloads.
Top performance on Arena-Hard v2, providing strong real-world alignment with human preference tasks.
Cost-efficient upgrade for teams wanting a powerful instruction model without jumping to ultra-large parameter sizes.
Well-balanced across domains, suitable for chat, code assistance, analysis, and evaluation tasks with predictable quality.
Thinking Model Performance
Exceptional deliberate reasoning with standout scores in math (AIME25: 87.8) and long-form logic tasks.
Better chain-of-thought efficiency, letting you achieve deeper reasoning quality while keeping token usage lower than giant models.
Strong alternative to expensive reasoning models, outperforming or matching models like Gemini 2.5 Flash Thinking at a lower parameter scale.
Ideal for decision-making, multi-step problem solving, and scientific workflows, where accuracy and depth matter more than speed.
High performance across coding and evaluation, making it valuable for engineering, research, and enterprise cognitive tasks.
How to Choose the Right API Provider?
Context Length (Higher is better): A larger context length lets the model read and process more text in a single run, supporting deeper summaries, longer conversations, and more complex reasoning.
Token Cost (Lower is better): A lower token cost means each piece of text processed is cheaper, making frequent queries and large scale workloads more budget friendly.
Latency (Lower is better): Lower latency means the model replies faster, creating smoother interactions that are important for assistants, chat tools, and real time systems.
Throughput (Higher is better): Higher throughput means the model can handle more requests at the same time, ensuring stable performance even during heavy usage.
Qwen3-Next-80B-A3B API Provider Comparison
Provider | Context Length | Input/Output Price | Output Speed (Tokens per sec) | Latency | Function Calling | JSON Mode |
Infron | 262K | $0.15/$1.5 per 1M Tokens | 147 | 0.89s | ✅ | ✅ |
Clarifai | 262K | $1.09/$1.08 per 1M Tokens | 175 | 0.32s | ❌ | ❌ |
Hyperbolic | 262K | $0.3/$0.3 per 1M Tokens | 323 | 0.77s | ❌ | ✅ |
Infron delivers the best overall value: the lowest prices, solid speed, and full support for function calling and JSON Mode. It offers the most cost-efficient and developer-friendly option for real production use. Clarifai offers a high token prices and lack of key features make it expensive and less practical for real-world scaling. Hyperbolic provides fast output speed but higher input cost and missing function calling limit its flexibility compared to Infron.
Top Qwen3-Next-80B-A3B API Provider: Infron
Infron provides a simplified API scheme where developers can call AI models right away using an easy-to-use API. By offering affordable, ready-to-use multimodal models like Qwen3-Next-80B-A3B, GLM 4.6, Kimi K2 Thinking, DeepSeek V3.2 Exp, GPT-OSS, and others, it eliminates configuration hassles and lets you begin building without delay.
How to Access via Infron API?
Infron provides a unified API that gives you access to hundreds of AI models through a single endpoint, while automatically handling fallbacks and selecting the most cost-effective options. Get started with just a few lines of code using your preferred SDK or framework.
Step 1: Log In and Access the Model Marketplace
Log in or sign up to your account and click on the Model Marketplace button
Step 2: Choose Your Model
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get API KEY
To authenticate with the API, Infron provides you with a new API key. Entering the “API Keys“ page, you can copy the API key as indicated in the image.
Step 5: Install the API
Install API using the package manager specific to your programming language.
Once the installation is complete, import the required libraries. Then, initialize the client with your API key to access the Infron LLM. The following snippet shows how Python users can work with the Chat Completions API.
from openai import OpenAI client = OpenAI( base_url="https://llm.onerouter.pro/v1", api_key="<API_KEY>", ) completion = client.chat.completions.create( model="qwen3-next-80b-a3b-instruct", messages=[ { "role": "user", "content": "What is the meaning of life?" } ] ) print(completion.choices[0].message.content)
Frequently Asked Questions
What is the Qwen3-Next-80B-A3B model?
It is a powerful large language model built on the Qwen3-Next architecture, offering advanced reasoning, strong coding ability, and exceptional performance while keeping inference efficient.
Does Qwen3-Next-80B-A3B support chain-of-thought reasoning?
Yes. The Thinking variant is optimized for multi-step reasoning, problem solving, math, and complex analysis tasks.
Which provider offers the best pricing for Qwen3-Next-80B-A3B?
Infron consistently delivers the lowest input cost and strong performance, making it the most cost-effective option for scaling real workloads. Try [Qwen3-Next-80B-A3B] for Free Now.
More Articles

LLM Tracing
LLM Tracing & Observability: A Guide to Debugging AI Apps
LLM Tracing
LLM Tracing & Observability: A Guide to Debugging AI Apps

LLM Hallucination Detection
LLM Hallucination Detection Methods: 5 Ways to Catch AI Errors
LLM Hallucination Detection
LLM Hallucination Detection Methods: 5 Ways to Catch AI Errors

AI Image models
5 Best AI Image Generation Models in 2026
AI Image models
5 Best AI Image Generation Models in 2026
Less orchestration.
More innovation.
Seamlessly integrate Infron with just a few lines of code and unlock unlimited AI power.
Less orchestration.
More innovation.
Seamlessly integrate Infron with just a few lines of code and unlock unlimited AI power.
Less orchestration.
More innovation.
Seamlessly integrate Infron with just a few lines of code and unlock unlimited AI power.