Smart LLM routing. Guaranteed throughput.
Infron Provisioned Throughput Plan: 10x Scale, 30% Lower LLM Costs

Date
Author
Andrew Zheng
Why LLM Rate Limits Keep Getting Worse Across Every AI Provider
Since Google released Gemini 2.5 Pro Preview on February 19, 2026, we've seen a flood of stability complaints across developer communities. Almost every inference platform has been affected to some degree. This hasn't just disrupted developer testing. It's caused serious operational problems for enterprises building production-grade applications on top of these models.
How AI API Rate Limiting Actually Works
Drawing on the architecture behind Microsoft Azure Provisioned Throughput, we can understand why large-scale AI inference services keep running into 429 errors.
Resource capacity constraints:
GPU compute is physically finite. Even when a user has a quota, that doesn't mean the system has reserved real-time compute capacity for them. Quota only limits the maximum number of PTUs (Provisioned Throughput Units). It does not guarantee that capacity is available at any given moment. Capacity is typically allocated dynamically at deployment time, and if regional capacity is insufficient, deployment fails outright.
Traffic bursts and rate limiting:
When user requests exceed the processing capacity of a deployment, the system returns HTTP 429. Most cloud providers use a leaky bucket algorithm to manage utilization. The moment instantaneous utilization exceeds 100%, the system immediately rejects requests and returns 429. Each request is evaluated for its expected utilization based on prompt token count, expected output token count, and model complexity.
Regional capacity shortages:
For high-demand models like Gemini 2.5 Pro and GPT-4o, capacity in specific regions frequently sells out. Concurrent demand from customers can instantly exceed the total available GPU capacity in a region.
Cost vs. performance tradeoffs:
Cloud providers have to balance operational cost against resource availability. Over-provisioning leads to enormous cost waste, while under-provisioning directly reduces availability.

What Happens to Your App When the Bucket Overflows
Unstable production environments: frequent errors result in a broken user experience
Unpredictable latency in real-time applications: routing around congested regions causes latency to spike unpredictably
Business interruptions: during critical moments like major promotions or product launches, services can go completely unavailable
SLA violations: impossible to guarantee service level agreements to end users
What Is Provisioned Throughput?
Core Concept
Infron, as an enterprise-grade AI model inference provider, is the first to introduce a Provisioned Throughput Plan. The plan is designed to help enterprise customers completely solve large-scale AI model inference stability problems through resource reservation and intelligent scheduling technology.
Core Features
Compared to traditional cloud providers' provisioned throughput offerings, Infron's solution makes significant improvements in flexibility and ease of use:
Broader model selection: supports the latest flagship models from Google Gemini, DeepSeek, OpenAI, and other providers, with the ability to switch flexibly between them
Flexible elastic scaling: no need to forecast peak usage in advance, no need to manage traffic shaping, provides an on-demand PT resource pool
Significant cost savings: more flexible reservation options improve resource utilization; partners can enjoy up to 35% discount; pay-as-you-go eliminates waste
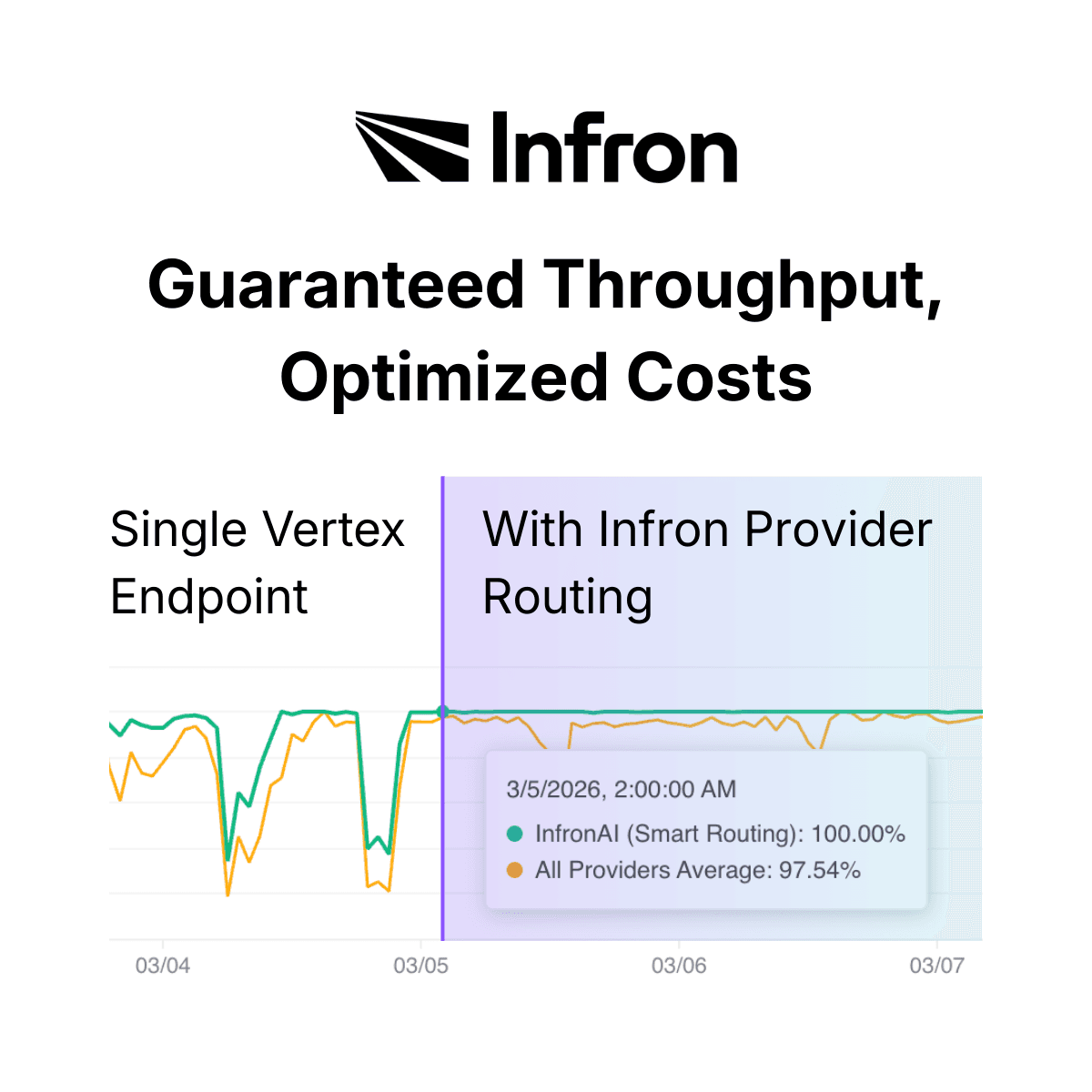
Predictable performance: stable maximum latency and throughput, bringing uptime from the industry average of 90% up to 99.99%
Intelligent LLM routing: automatically selects the best provider, balancing performance, latency, and cost; supports custom priority and fallback strategies
Flexible resource scheduling: through flexible PT resource dispatch, significantly improves stability for new models like Gemini 2.5 Pro Preview
The Value of Infron's Provisioned Throughput Plan for Enterprise
Benefit | Description |
|---|---|
Flexible scaling | No usage forecasting required. No commitment consumption. Avoid financial waste. Scale instantly with pay-as-you-go. |
Flexibility | Switch between model providers using configurable routing rules. Dynamically adjust strategy based on business needs. |
Significant discounts | More flexible reservation options improve reservation utilization. Partners enjoy up to 35% discount. |
Cost savings | Reduce cost waste. Optimize resource utilization. |
Predictable performance | Stable maximum latency and throughput. Minimize cost overhead. 99.99% availability guaranteed. |
Infron Solution Architecture
Dual Guarantee Plan
Infron currently offers two resource guarantee modes for Gemini 2.5 Pro Preview, designed to meet the needs of different scenarios.
Mode 1: Cost-Availability Balance (Default) | Mode 2: Maximum Availability (PT Plan) | |
|---|---|---|
Uptime | 99~99.5% | 99.99~100% |
Cost structure | Up to 35% discount | Average cost +0~35% above standard |
How it works | Call Infron's API endpoint directly in the standard way (e.g. | Infron introduces Google's Provisioned Throughput Provider. This is an optional configuration (disabled by default). When a user explicitly specifies "high-availability routing" via parameter, Infron schedules the request into Google's high-priority resource pool. |
Best for | Cost-sensitive workloads, non-critical business paths | Routine requests (no parameter needed, uses cost-optimized routing), retry scenarios (route to PT on 429), critical business requests that must succeed |
Core goal | Maximize availability while minimizing cost | Maintain business continuity for high-stability requirements, especially during periods of global resource instability |
Technical Advantages: Infron vs. Traditional Cloud Providers
Compared to traditional cloud providers like Azure, Infron offers a fundamentally different approach to provisioned throughput.
Limitations of traditional solutions (Azure and others):
Must forecast peak business usage in advance
Must predict the exact timing of resource demand
Must manage traffic shaping yourself
Only suitable for production applications with known, predictable traffic patterns
Infron's advantages:
No forecasting: no need to predict peak business usage in advance
Always ready: no need to predict when resources will be needed
Automatic management: no need to manage traffic shaping yourself
Truly on-demand: an instantly available PT resource pool, real pay-as-you-go
When to Use Infron's Provisioned Throughput Plan
No more forecasting or planning required. Unlike traditional cloud providers, Infron's PT Plan does not require you to:
Forecast peak business usage in advance
Predict the exact timing of resource demand
Manage traffic shaping yourself
The right fit for these scenarios:
Unpredictable traffic applications. Fast-growing businesses, high-volatility workloads, or teams in early-stage experimentation where it's difficult to forecast actual usage.
Applications with extremely high availability requirements. Critical production business paths, real-time interactive applications like customer service bots, and latency-sensitive applications.
Cost-sensitive applications that still need high availability. Teams that want to optimize cost while maintaining availability, and avoid resource waste from over-provisioning.
Applications requiring flexible multi-model switching. Teams that need to switch between cloud providers, test different model performance, or dynamically select the best model based on business requirements.
How to Get Infron's Provisioned Throughput Plan
Infron offers two simple ways to get started. No complex configuration or reservation process required.
Default Mode: Cost-Optimized LLM Routing
No extra configuration needed. Use the standard API call. The system automatically balances cost, performance, and availability.
import requests headers = { 'Authorization': 'Bearer <YOUR_API_KEY>', 'Content-Type': 'application/json' } response = requests.post('https://llm.onerouter.pro/v1/chat/completions', headers=headers, json={ 'model': 'google/gemini-2.5-pro-preview', 'messages': [{'role': 'user', 'content': 'Hello'}] } )
import requests headers = { 'Authorization': 'Bearer <YOUR_API_KEY>', 'Content-Type': 'application/json' } response = requests.post('https://llm.onerouter.pro/v1/chat/completions', headers=headers, json={ 'model': 'google/gemini-2.5-pro-preview', 'messages': [{'role': 'user', 'content': 'Hello'}] } )
PT Mode: High-Availability Routing for Critical Requests
Enable high-availability routing via the Provider Routing parameter. Requests are routed to the high-priority resource pool.
import requests headers = { 'Authorization': 'Bearer <YOUR_API_KEY>', 'Content-Type': 'application/json' } response = requests.post('https://llm.onerouter.pro/v1/chat/completions', headers=headers, json={ 'model': 'google/gemini-2.5-pro-preview', 'messages': [{'role': 'user', 'content': 'Hello'}], 'provider': { 'order': ['google-vertex/pt'], # prioritize PT resource pool 'allow_fallbacks': True # allow fallback to other providers } } )
import requests headers = { 'Authorization': 'Bearer <YOUR_API_KEY>', 'Content-Type': 'application/json' } response = requests.post('https://llm.onerouter.pro/v1/chat/completions', headers=headers, json={ 'model': 'google/gemini-2.5-pro-preview', 'messages': [{'role': 'user', 'content': 'Hello'}], 'provider': { 'order': ['google-vertex/pt'], # prioritize PT resource pool 'allow_fallbacks': True # allow fallback to other providers } } )
Smart Retry: Combining Both LLM Routing Strategies
Combine both modes for an intelligent retry mechanism: use the low-cost mode by default, and automatically escalate to PT mode on 429 errors.
import requests import time def call_with_retry(messages, max_retries=3): headers = { 'Authorization': 'Bearer <YOUR_API_KEY>', 'Content-Type': 'application/json' } # First attempt: cost-optimized routing try: response = requests.post( 'https://llm.onerouter.pro/v1/chat/completions', headers=headers, json={ 'model': 'google/gemini-2.5-pro-preview', 'messages': messages } ) if response.status_code == 200: return response.json() except Exception as e: print(f"First attempt failed: {e}") # Retry: escalate to PT high-availability routing for attempt in range(max_retries): try: response = requests.post( 'https://llm.onerouter.pro/v1/chat/completions', headers=headers, json={ 'model': 'google/gemini-2.5-pro-preview', 'messages': messages, 'provider': { 'order': ['google-vertex/pt'], 'allow_fallbacks': True } } ) if response.status_code == 200: return response.json() if response.status_code == 429: retry_after = int(response.headers.get('retry-after-ms', 1000)) / 1000 time.sleep(retry_after) except Exception as e: print(f"Retry {attempt + 1} failed: {e}") time.sleep(2 ** attempt) # exponential backoff raise Exception("All retries failed")
import requests import time def call_with_retry(messages, max_retries=3): headers = { 'Authorization': 'Bearer <YOUR_API_KEY>', 'Content-Type': 'application/json' } # First attempt: cost-optimized routing try: response = requests.post( 'https://llm.onerouter.pro/v1/chat/completions', headers=headers, json={ 'model': 'google/gemini-2.5-pro-preview', 'messages': messages } ) if response.status_code == 200: return response.json() except Exception as e: print(f"First attempt failed: {e}") # Retry: escalate to PT high-availability routing for attempt in range(max_retries): try: response = requests.post( 'https://llm.onerouter.pro/v1/chat/completions', headers=headers, json={ 'model': 'google/gemini-2.5-pro-preview', 'messages': messages, 'provider': { 'order': ['google-vertex/pt'], 'allow_fallbacks': True } } ) if response.status_code == 200: return response.json() if response.status_code == 429: retry_after = int(response.headers.get('retry-after-ms', 1000)) / 1000 time.sleep(retry_after) except Exception as e: print(f"Retry {attempt + 1} failed: {e}") time.sleep(2 ** attempt) # exponential backoff raise Exception("All retries failed")
Advanced LLM Routing Configuration
Infron supports a range of routing configuration options:
Sort by price:
'sort': 'price'Sort by latency:
'sort': 'latency', 'preferred_max_latency': {'p90': 3}Sort by throughput:
'sort': 'throughput'Data compliance:
'data_collection': 'deny'(refuse to store user data)
Conclusion
Infron's Provisioned Throughput Plan delivers a flexible, efficient, high-availability AI inference solution for enterprise through innovative flexible resource scheduling and intelligent LLM routing.
No forecasting: no need to predict business usage or resource demand in advance
Flexible scaling: true on-demand elastic scaling, ready when you need it
High availability: uptime lifted from 90% to 99.99%
Cost optimization: intelligent routing balances cost and performance, saving up to 35%
Unlike traditional cloud providers that require advance planning and resource reservation, Infron lets enterprises truly benefit from the elasticity and flexibility of cloud services, so teams can focus on building products rather than managing infrastructure.
Infron's Provisioned Throughput Plan is available now. Get started at infron.ai with the standard API. No upfront commitment or capacity reservation required.
Why LLM Rate Limits Keep Getting Worse Across Every AI Provider
Since Google released Gemini 2.5 Pro Preview on February 19, 2026, we've seen a flood of stability complaints across developer communities. Almost every inference platform has been affected to some degree. This hasn't just disrupted developer testing. It's caused serious operational problems for enterprises building production-grade applications on top of these models.
How AI API Rate Limiting Actually Works
Drawing on the architecture behind Microsoft Azure Provisioned Throughput, we can understand why large-scale AI inference services keep running into 429 errors.
Resource capacity constraints:
GPU compute is physically finite. Even when a user has a quota, that doesn't mean the system has reserved real-time compute capacity for them. Quota only limits the maximum number of PTUs (Provisioned Throughput Units). It does not guarantee that capacity is available at any given moment. Capacity is typically allocated dynamically at deployment time, and if regional capacity is insufficient, deployment fails outright.
Traffic bursts and rate limiting:
When user requests exceed the processing capacity of a deployment, the system returns HTTP 429. Most cloud providers use a leaky bucket algorithm to manage utilization. The moment instantaneous utilization exceeds 100%, the system immediately rejects requests and returns 429. Each request is evaluated for its expected utilization based on prompt token count, expected output token count, and model complexity.
Regional capacity shortages:
For high-demand models like Gemini 2.5 Pro and GPT-4o, capacity in specific regions frequently sells out. Concurrent demand from customers can instantly exceed the total available GPU capacity in a region.
Cost vs. performance tradeoffs:
Cloud providers have to balance operational cost against resource availability. Over-provisioning leads to enormous cost waste, while under-provisioning directly reduces availability.
What Happens to Your App When the Bucket Overflows
Unstable production environments: frequent errors result in a broken user experience
Unpredictable latency in real-time applications: routing around congested regions causes latency to spike unpredictably
Business interruptions: during critical moments like major promotions or product launches, services can go completely unavailable
SLA violations: impossible to guarantee service level agreements to end users
What Is Provisioned Throughput?
Core Concept
Infron, as an enterprise-grade AI model inference provider, is the first to introduce a Provisioned Throughput Plan. The plan is designed to help enterprise customers completely solve large-scale AI model inference stability problems through resource reservation and intelligent scheduling technology.
Core Features
Compared to traditional cloud providers' provisioned throughput offerings, Infron's solution makes significant improvements in flexibility and ease of use:
Broader model selection: supports the latest flagship models from Google Gemini, DeepSeek, OpenAI, and other providers, with the ability to switch flexibly between them
Flexible elastic scaling: no need to forecast peak usage in advance, no need to manage traffic shaping, provides an on-demand PT resource pool
Significant cost savings: more flexible reservation options improve resource utilization; partners can enjoy up to 35% discount; pay-as-you-go eliminates waste
Predictable performance: stable maximum latency and throughput, bringing uptime from the industry average of 90% up to 99.99%
Intelligent LLM routing: automatically selects the best provider, balancing performance, latency, and cost; supports custom priority and fallback strategies
Flexible resource scheduling: through flexible PT resource dispatch, significantly improves stability for new models like Gemini 2.5 Pro Preview
The Value of Infron's Provisioned Throughput Plan for Enterprise
Benefit | Description |
|---|---|
Flexible scaling | No usage forecasting required. No commitment consumption. Avoid financial waste. Scale instantly with pay-as-you-go. |
Flexibility | Switch between model providers using configurable routing rules. Dynamically adjust strategy based on business needs. |
Significant discounts | More flexible reservation options improve reservation utilization. Partners enjoy up to 35% discount. |
Cost savings | Reduce cost waste. Optimize resource utilization. |
Predictable performance | Stable maximum latency and throughput. Minimize cost overhead. 99.99% availability guaranteed. |
Infron Solution Architecture
Dual Guarantee Plan
Infron currently offers two resource guarantee modes for Gemini 2.5 Pro Preview, designed to meet the needs of different scenarios.
Mode 1: Cost-Availability Balance (Default) | Mode 2: Maximum Availability (PT Plan) | |
|---|---|---|
Uptime | 99~99.5% | 99.99~100% |
Cost structure | Up to 35% discount | Average cost +0~35% above standard |
How it works | Call Infron's API endpoint directly in the standard way (e.g. | Infron introduces Google's Provisioned Throughput Provider. This is an optional configuration (disabled by default). When a user explicitly specifies "high-availability routing" via parameter, Infron schedules the request into Google's high-priority resource pool. |
Best for | Cost-sensitive workloads, non-critical business paths | Routine requests (no parameter needed, uses cost-optimized routing), retry scenarios (route to PT on 429), critical business requests that must succeed |
Core goal | Maximize availability while minimizing cost | Maintain business continuity for high-stability requirements, especially during periods of global resource instability |
Technical Advantages: Infron vs. Traditional Cloud Providers
Compared to traditional cloud providers like Azure, Infron offers a fundamentally different approach to provisioned throughput.
Limitations of traditional solutions (Azure and others):
Must forecast peak business usage in advance
Must predict the exact timing of resource demand
Must manage traffic shaping yourself
Only suitable for production applications with known, predictable traffic patterns
Infron's advantages:
No forecasting: no need to predict peak business usage in advance
Always ready: no need to predict when resources will be needed
Automatic management: no need to manage traffic shaping yourself
Truly on-demand: an instantly available PT resource pool, real pay-as-you-go
When to Use Infron's Provisioned Throughput Plan
No more forecasting or planning required. Unlike traditional cloud providers, Infron's PT Plan does not require you to:
Forecast peak business usage in advance
Predict the exact timing of resource demand
Manage traffic shaping yourself
The right fit for these scenarios:
Unpredictable traffic applications. Fast-growing businesses, high-volatility workloads, or teams in early-stage experimentation where it's difficult to forecast actual usage.
Applications with extremely high availability requirements. Critical production business paths, real-time interactive applications like customer service bots, and latency-sensitive applications.
Cost-sensitive applications that still need high availability. Teams that want to optimize cost while maintaining availability, and avoid resource waste from over-provisioning.
Applications requiring flexible multi-model switching. Teams that need to switch between cloud providers, test different model performance, or dynamically select the best model based on business requirements.
How to Get Infron's Provisioned Throughput Plan
Infron offers two simple ways to get started. No complex configuration or reservation process required.
Default Mode: Cost-Optimized LLM Routing
No extra configuration needed. Use the standard API call. The system automatically balances cost, performance, and availability.
import requests headers = { 'Authorization': 'Bearer <YOUR_API_KEY>', 'Content-Type': 'application/json' } response = requests.post('https://llm.onerouter.pro/v1/chat/completions', headers=headers, json={ 'model': 'google/gemini-2.5-pro-preview', 'messages': [{'role': 'user', 'content': 'Hello'}] } )
PT Mode: High-Availability Routing for Critical Requests
Enable high-availability routing via the Provider Routing parameter. Requests are routed to the high-priority resource pool.
import requests headers = { 'Authorization': 'Bearer <YOUR_API_KEY>', 'Content-Type': 'application/json' } response = requests.post('https://llm.onerouter.pro/v1/chat/completions', headers=headers, json={ 'model': 'google/gemini-2.5-pro-preview', 'messages': [{'role': 'user', 'content': 'Hello'}], 'provider': { 'order': ['google-vertex/pt'], # prioritize PT resource pool 'allow_fallbacks': True # allow fallback to other providers } } )
Smart Retry: Combining Both LLM Routing Strategies
Combine both modes for an intelligent retry mechanism: use the low-cost mode by default, and automatically escalate to PT mode on 429 errors.
import requests import time def call_with_retry(messages, max_retries=3): headers = { 'Authorization': 'Bearer <YOUR_API_KEY>', 'Content-Type': 'application/json' } # First attempt: cost-optimized routing try: response = requests.post( 'https://llm.onerouter.pro/v1/chat/completions', headers=headers, json={ 'model': 'google/gemini-2.5-pro-preview', 'messages': messages } ) if response.status_code == 200: return response.json() except Exception as e: print(f"First attempt failed: {e}") # Retry: escalate to PT high-availability routing for attempt in range(max_retries): try: response = requests.post( 'https://llm.onerouter.pro/v1/chat/completions', headers=headers, json={ 'model': 'google/gemini-2.5-pro-preview', 'messages': messages, 'provider': { 'order': ['google-vertex/pt'], 'allow_fallbacks': True } } ) if response.status_code == 200: return response.json() if response.status_code == 429: retry_after = int(response.headers.get('retry-after-ms', 1000)) / 1000 time.sleep(retry_after) except Exception as e: print(f"Retry {attempt + 1} failed: {e}") time.sleep(2 ** attempt) # exponential backoff raise Exception("All retries failed")
Advanced LLM Routing Configuration
Infron supports a range of routing configuration options:
Sort by price:
'sort': 'price'Sort by latency:
'sort': 'latency', 'preferred_max_latency': {'p90': 3}Sort by throughput:
'sort': 'throughput'Data compliance:
'data_collection': 'deny'(refuse to store user data)
Conclusion
Infron's Provisioned Throughput Plan delivers a flexible, efficient, high-availability AI inference solution for enterprise through innovative flexible resource scheduling and intelligent LLM routing.
No forecasting: no need to predict business usage or resource demand in advance
Flexible scaling: true on-demand elastic scaling, ready when you need it
High availability: uptime lifted from 90% to 99.99%
Cost optimization: intelligent routing balances cost and performance, saving up to 35%
Unlike traditional cloud providers that require advance planning and resource reservation, Infron lets enterprises truly benefit from the elasticity and flexibility of cloud services, so teams can focus on building products rather than managing infrastructure.
Infron's Provisioned Throughput Plan is available now. Get started at infron.ai with the standard API. No upfront commitment or capacity reservation required.
More Articles

LLM Tracing
LLM Tracing & Observability: A Guide to Debugging AI Apps
LLM Tracing
LLM Tracing & Observability: A Guide to Debugging AI Apps

LLM Hallucination Detection
LLM Hallucination Detection Methods: 5 Ways to Catch AI Errors
LLM Hallucination Detection
LLM Hallucination Detection Methods: 5 Ways to Catch AI Errors

AI Image models
5 Best AI Image Generation Models in 2026
AI Image models
5 Best AI Image Generation Models in 2026
Less orchestration.
More innovation.
Seamlessly integrate Infron with just a few lines of code and unlock unlimited AI power.
Less orchestration.
More innovation.
Seamlessly integrate Infron with just a few lines of code and unlock unlimited AI power.
Less orchestration.
More innovation.
Seamlessly integrate Infron with just a few lines of code and unlock unlimited AI power.