A Technical Roadmap for R&D Teams
Top AI Model for Roleplay: The R&D Selection Guide

Date
Author
Andrew Zheng
The Revolutionary Evolution of AI Models for Roleplay
As artificial intelligence continues to advance through 2026, roleplay AI models have become essential tools in creative writing, interactive storytelling, game development, and conversational systems. These specialized large language models (LLMs) don't just maintain coherent long-form conversations, they understand complex character settings, emotional nuances, and narrative continuity.
This guide evaluates the 10 best roleplay models of 2026, spanning the 8B to 70B spectrum. Whether you are optimizing for edge-device efficiency or flagship multimodal performance, you’ll find the technical breakdown needed to select the optimal engine for your narrative architecture.

Quick Comparison: Top 10 Roleplay AI Models at a Glance
Model | Parameters | Architecture | Context Window | Pricing | Key Feature |
|---|---|---|---|---|---|
L3.1-70B-Euryale-v2.2 | 70B | Llama 3.1 | 16,000 tokens | $3/M tokens | Multi-turn coherence |
L3.1-70B-Hanami-x1 | 70B | Llama 3.1 | 16,000 tokens | $3/M tokens | Text + Vision |
Cydonia-22B-v1 | 22B | - | - | - | Performance-efficiency balance |
MN-Violet-Lotus-12B | 12B | Mistral-NeMo | - | - | EQ score 80.00 |
MN-12B-Lyra-v4 | 12B | Mistral-NeMo | - | - | Direct RL training |
Chronos-Gold-12B-1.0 | 12B | - | - | - | 2,250 token output |
Lyra_Gutenbergs-Twilight_Magnum-12B | 12B | Mistral-NeMo | - | - | Double Back SLERP merge |
L3-8B-Lunaris-v1 | 8B | Llama 3 | 8,200 tokens | $0.04-0.05/M | Lowest cost |
Captain_BMO-12B | 12B | - | - | - | Emerging challenger |
1. Sao10K/L3.1-70B-Euryale-v2.2 - Flagship Multimodal Roleplay Engine
Core Specifications
Parameter Scale: 70B
Architecture Base: Llama 3.1
Context Window: 16,000 tokens
Pricing: $3 per million tokens
Standout Features
L3.1-70B-Euryale-v2.2 represents the pinnacle of Sao10K's work, refined through a two-stage optimization process. The first stage focused on multi-turn conversational instructions, while the second deepened creative writing and roleplay capabilities. During training, the model incorporated human-generated content alongside high-quality data from Claude 3.5 Sonnet and Claude 3 Opus.
Core Advantages:
Enhanced Multi-Turn Coherence: Through specialized multi-turn dialogue datasets, significantly improved context maintenance across extended conversations
Amplified Creative Writing: Contains 55% more roleplay examples (from Gryphe's Sonnet3.5-Charcard-Roleplay dataset) and 40% more creative writing cases
Optimized Instruction Following: Integrated dedicated datasets for system prompt adherence, reasoning, and spatial awareness
Refined Data Quality: Single-turn instruction data replaced with high-quality prompts and responses, extensively filtered to reduce errors
Recommended Configuration: Use Llama 3.1 Instruct format with Euryale 2.1 preset, temperature of 1.2, and min_p of 0.2 for optimal creative and conversational output.
Learn more: Sao10K/L3.1-70B-Euryale-v2.2
2. Sao10K/L3.1-70B-Hanami-x1 - Multimodal Master of Vision and Text Fusion
Core Specifications
Parameter Scale: 70B
Architecture Base: Llama 3.1
Context Window: 16,000 tokens
Multimodal Capability: Text + Visual (image) input
Pricing: $3 per million tokens
Revolutionary Features
L3.1-70B-Hanami-x1 represents the next evolutionary stage of roleplay AI—true multimodal understanding. Released on January 8, 2025, this model can process both text and image inputs simultaneously, creating entirely new possibilities for visual novels, game roleplay, and immersive narrative experiences.
Technical Highlights:
Native Image Processing: Equipped with a specialized vision encoder that understands image content and seamlessly integrates it with text
Extended Context Capability: 16,000 tokens equals approximately 12,000-14,000 words, handling complete research papers or extensive conversation histories
OpenAI-Compatible API: Integrates smoothly into existing workflows
Cross-Platform Availability: Available on NeuroRouters, Infron, Featherless.ai, Ragwalla, and Ridvay
Application Scenarios:
Customer support roleplay with screenshot analysis
Creative content generation with image references
Visual novel-style interactive narratives
Educational roleplay scenarios (combining charts and textual explanations)
Learn more: Sao10K/L3.1-70B-Hanami-x1
3. TheDrummer/Cydonia-22B-v1 - Mid-Size High-Performance Roleplay Specialist
Core Specifications
Parameter Scale: 22B
Developer: TheDrummer
Platform Support: Infron AI
Strategic Positioning
Cydonia-22B-v1 strikes the ideal balance between performance and efficiency. The 22B parameter scale allows it to run on moderate hardware while delivering output quality approaching that of larger models. This makes it the best choice for high-quality roleplay in resource-constrained environments.
Key Advantages:
Cost-Effectiveness: Lower inference costs compared to 70B models
Deployment Flexibility: Can be deployed on mid-tier GPU infrastructure
Performance Balance: Maintains high-quality output while reducing computational demands
Learn more: TheDrummer/Cydonia-22B-v1
4. FallenMerick/MN-Violet-Lotus-12B - King of Emotional Intelligence in Roleplay
Core Specifications
Parameter Scale: 12B
Architecture Base: Mistral-NeMo
Emotional Intelligence Score: 80.00 (Local EQ Benchmark)
Merge Method: Model Stock
The Art of Emotional Expression
MN-Violet-Lotus-12B is a masterpiece crafted by FallenMerick using the Model Stock method, merging four specialized base models:
Epiculous/Violet_Twilight-v0.2
NeverSleep/Lumimaid-v0.2-12B
flammenai/Mahou-1.5-mistral-nemo-12B
Sao10K/MN-12B-Lyra-v4
Unique Advantages:
Exceptional Emotional Intelligence: Excels at understanding and expressing emotional nuances with an EQ score of 80.00
Character Consistency: Maintains diverse character personalities and adapts to various roleplay scenarios
Quality Creative Output: Produces high-quality, imaginative text while avoiding excessive verbosity
Optimized Writing Style: Particularly focuses on balancing coherence and creativity in outputs
Recommended Applications:
Roleplay requiring deep emotional expression
Psychological counseling simulation scenarios
Literary creation and character development
Emotion-driven interactive narratives
Learn more: FallenMerick/MN-Violet-Lotus-12B
5. Sao10K/MN-12B-Lyra-v4 - Reinforcement Learning-Driven Instruction Expert
Core Specifications
Parameter Scale: 12B
Architecture Base: Mistral-NeMo
License: CC-BY-NC-4.0
Supported Formats: ChatML and variants
Innovative Methodology
MN-12B-Lyra-v4 employs a unique reinforcement learning path—training directly on instruction and coherence with the base NeMo model, rather than the traditional SFT-first approach. This innovation has led to better quantization handling and more stable performance.
Technical Innovations:
Direct Reinforcement Learning: Skips traditional SFT stage to directly optimize instruction-following capabilities
Enhanced Tokenizer Configuration: Improved stability and token generation quality
Multi-Format Dialogue Support: Full support for ChatML and its variants
Optimized Sampling Strategy: Recommended temperature range 0.6-1.0, min_p values 0.1-0.2
Best Use Cases:
Structured dialogue interactions
Roleplay requiring precise instruction following
Context-aware conversational scenarios
Enterprise-grade chatbot development
Learn more: Sao10K/MN-12B-Lyra-v4
6. Elinas/Chronos-Gold-12B-1.0 - Long-Form Text Generation Specialist
Core Specifications
Parameter Scale: 12B
Maximum Output Length: 2,250 tokens
Developer Organization: Elina Education
Platform Support: Featherless.ai, Infron
Extended Output Capability
The standout feature of Chronos-Gold-12B-1.0 is its ability to generate up to 2,250 tokens in a single output while maintaining coherence and contextual relevance—a significant advantage for applications requiring detailed, nuanced responses.
Core Capabilities:
Ultra-Long Output Maintenance: Maintains narrative coherence throughout extended generation
Dialogue Optimization: Architecture specifically optimized for dialogue-intensive scenarios
General Chatbot Functionality: Handles diverse conversational topics
Roleplay Adaptability: Suitable for scenarios requiring detailed scene descriptions and complex character interactions
Ideal Applications:
Interactive storytelling (requiring long-form narratives)
Detailed scene description generation
Customer service automation (complex queries)
Educational content creation
Learn more: Elinas/Chronos-Gold-12B-1.0
7. ChaoticNeutrals/Lyra_Gutenbergs-Twilight_Magnum-12B - Literary Style Fusion Model
Core Specifications
Parameter Scale: 12B
Architecture Base: Mistral-NeMo
Merge Method: Double Back SLERP
Supported Formats: Mistral and ChatML
Fusion of Literary DNA
Lyra_Gutenbergs-Twilight_Magnum-12B is a carefully designed fusion model that integrates three original models through the Double Back SLERP merge method:
Anthracite-org/magnum-v2.5-12b-kto
Nbeerbower/Lyra-Gutenberg-mistral-nemo-12B
Epiculous/Violet_Twilight-v0.1
Unique Characteristics:
ShareGPT Format Optimization: Deeply optimized for ShareGPT data format (what the developer calls "ShareGPT Formaxxing")
Dual Format Support: Compatible with both Mistral and ChatML instruction formats
Balanced Literary Style: Fuses literary style characteristics from multiple models, creating a unique writing voice
Community-Driven: An innovative experimental result from the HuggingFace community
Configuration Note: When using SillyTavern with ChatML format, add ["<|im_end|"] to custom stop strings to prevent ChatML EOS token leakage into conversations.
Learn more: ChaoticNeutrals/Lyra_Gutenbergs-Twilight_Magnum-12B
8. Sao10K/L3-8B-Lunaris-v1 - Lightweight Creative and Logic Balancer
Core Specifications
Parameter Scale: 8B
Architecture Base: Llama 3
Context Window: 8.2K tokens
Pricing: Input $0.04/million tokens, Output $0.05/million tokens
Small Yet Powerful
L3-8B-Lunaris-v1 is a versatile general-purpose and roleplay model based on the Llama 3 architecture. Through strategically merging multiple models, it aims to balance creativity with improved logic and general knowledge.
Competitive Advantages:
Ultimate Cost-Effectiveness: Lowest pricing among all recommended models
Fast Response: Smaller parameter scale means faster inference speeds
Balanced Design: Finds optimal equilibrium between creativity, logical reasoning, and knowledge breadth
Easy Deployment: Can run on entry-level GPUs
Suitable Scenarios:
Budget-limited projects
Real-time roleplay applications requiring quick responses
Mobile or edge device deployment
Prototype development and testing phases
Learn more: Sao10K/L3-8B-Lunaris-v1
9. Nitral-AI/Captain_BMO-12B - Emerging Roleplay Challenger
Core Specifications
Parameter Scale: 12B
Developer: Nitral-AI
Platform Support: Infron
Next-Generation Exploration
Captain_BMO-12B represents Nitral-AI's latest exploration in the roleplay AI space. While detailed technical information is limited, the 12B parameter scale positions it in the mid-tier efficient model category, suitable for applications balancing performance and resource consumption.
Strategic Value:
Mid-Range Parameter Scale: Offers a good compromise between quality and efficiency
Community Attention: As an emerging model, closely watched by the AI community
Continuous Evolution: Promising significant improvements in subsequent versions
Learn more: Nitral-AI/Captain_BMO-12B
10. Honorable Mentions: Community Favorites and Rising Stars
Beyond the nine models detailed above, the roleplay AI ecosystem contains many emerging models and experimental projects worth watching:
Fine-Tuned and Quantized Versions
Many base models have community-created GGUF quantized versions that can run under lower hardware requirements. For example, BackyardAI and mradermacher provide multiple quantized versions of MN-Violet-Lotus-12B.
Domain-Specific Models
Some models are optimized for specific types of roleplay, such as fantasy settings, science fiction scenarios, or narratives with particular cultural backgrounds.
How to Choose the Best LLM for roleplay: Decision Framework
1. Selection by Parameter Scale
Parameter Scale | Suitable Scenarios | Recommended Models |
|---|---|---|
8B | Budget-constrained, rapid prototyping, edge deployment | L3-8B-Lunaris-v1 |
12B | Balance performance and cost, medium-complexity tasks | MN-Violet-Lotus-12B, MN-12B-Lyra-v4, Chronos-Gold-12B |
22B | Higher quality needs while controlling costs | Cydonia-22B-v1 |
70B | Highest quality requirements, complex multimodal tasks | L3.1-70B-Euryale-v2.2, L3.1-70B-Hanami-x1 |
2. Selection by Core Capability
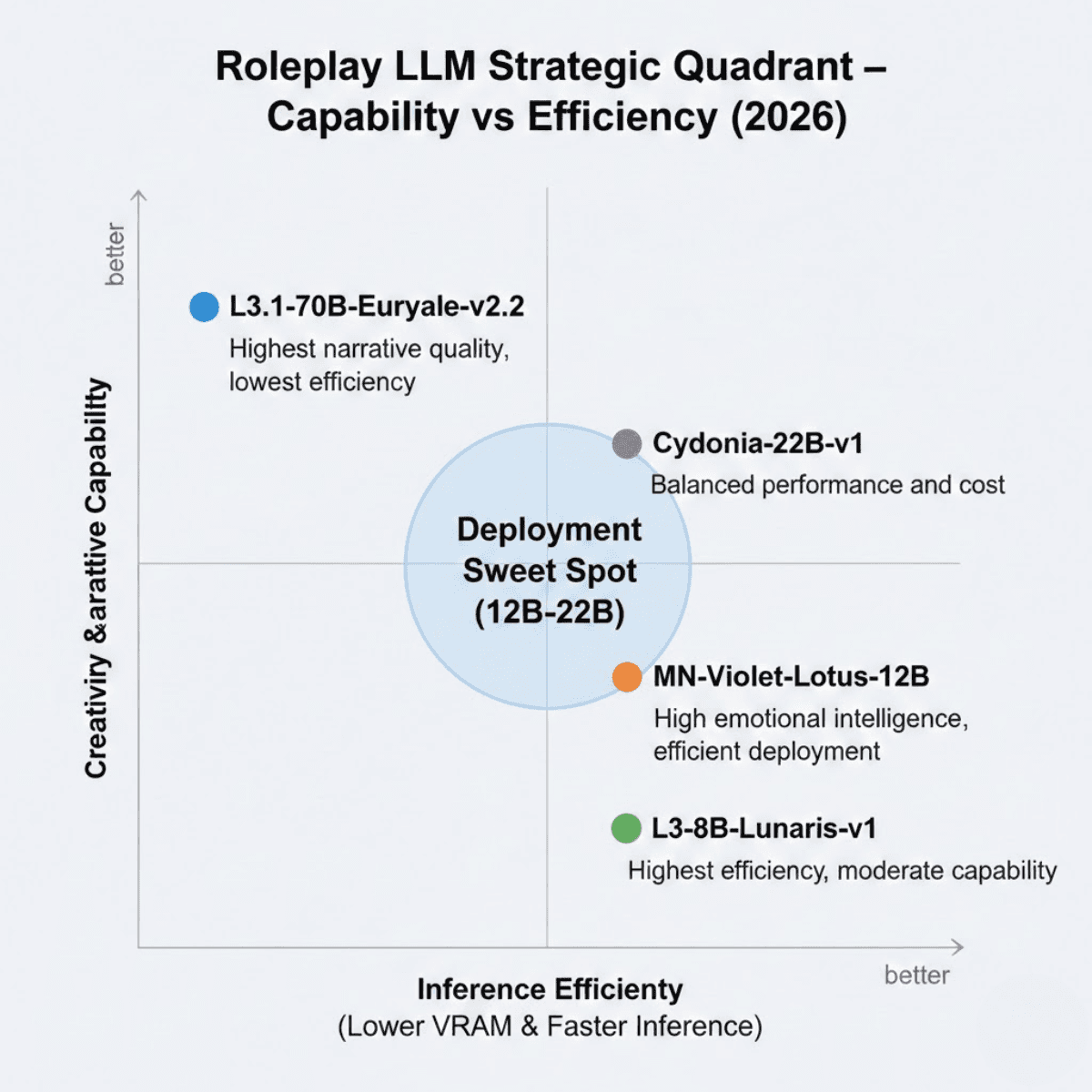
Best Emotional Intelligence: MN-Violet-Lotus-12B (EQ score 80.00)
Best Multimodal Capability: L3.1-70B-Hanami-x1 (Text + Vision)
Best Instruction Following: MN-12B-Lyra-v4 (Reinforcement learning optimized)
Longest Output Capability: Chronos-Gold-12B-1.0 (2,250 tokens)
Best Multi-Turn Dialogue: L3.1-70B-Euryale-v2.2 (Multi-turn coherence optimized)
Best Value for Money: L3-8B-Lunaris-v1 ($0.04-0.05/million tokens)
3. Selection by Application Scenario
Game Development:
First choice: L3.1-70B-Hanami-x1 (visual integration)
Alternative: MN-Violet-Lotus-12B (emotional expression)
Creative Writing:
First choice: L3.1-70B-Euryale-v2.2 (creative writing enhanced)
Alternative: Lyra_Gutenbergs-Twilight_Magnum-12B (literary style)
Customer Service:
First choice: MN-12B-Lyra-v4 (instruction following)
Alternative: Chronos-Gold-12B-1.0 (detailed responses)
Budget-Constrained Projects:
First choice: L3-8B-Lunaris-v1 (lowest cost)
Alternative: Any 12B model (moderate cost)
Best Practices for AI Model for Roleplay in 2026
1. Prompt Engineering Optimization
According to the latest 2026 research, high-quality prompt engineering is critical for roleplay effectiveness:
Provide Clear Character Background: Include character history, personality traits, speaking style, and motivations
Set Explicit Scene Context: Describe environment, time period, atmosphere, and relevant background information
Use System Prompts: Leverage the model's system prompt functionality to establish tone and behavioral guidelines
Iterative Refinement: Gradually adjust prompting strategies based on output quality
2. Parameter Tuning Strategies
Different models require different sampling parameter configurations:
Parameter | Value Range | Effect | Best For |
|---|---|---|---|
Temperature | |||
Low | 0.6-0.8 | More consistent, predictable outputs | Structured dialogue |
Medium | 0.8-1.2 | Balance creativity and coherence | General roleplay |
High | 1.2-1.5 | Maximize creativity and diversity | Experimental scenarios |
Min-p | 0.1-0.2 | Controls output filtering | NeMo-based models |
Top-p | 0.9-0.95 | Controls output diversity | All models |
Frequency Penalty | - | Reduces word repetition | Avoiding repetitive vocabulary |
Presence Penalty | - | Encourages new topics | Introducing variety |
Repetition Penalty | - | Avoids sentence pattern repetition | Preventing monotonous output |
3. Context Management Techniques
Effectively Using Context Windows:
Regularly summarize long conversations to compress context
Prioritize retention of key information (character settings, important plot points)
For ultra-long scenarios, consider segmented processing
RAG Integration:
Use Retrieval-Augmented Generation (RAG) to extend model knowledge
Integrate character cards, world settings, and reference materials
Retrieve relevant context in real-time rather than loading everything
4. Multimodal Application Strategies
For models supporting visual input (like L3.1-70B-Hanami-x1):
Image Preprocessing: Ensure images are clear with appropriate resolution
Text-Image Alignment: Explicitly reference image content in prompts
Progressive Multimodality: Establish text context first, then introduce visual elements
5. Safety and Ethical Considerations
Content Filtering: Implement appropriate output review mechanisms
User Privacy: Don't share sensitive personal information with AI
Boundary Setting: Clearly communicate the virtual nature of AI roleplay
Copyright Awareness: Ensure generated content complies with copyright laws
Performance Benchmarking: 2026 AI Model for Roleplay Comparison
Model Name | Parameter Scale | Emotional Expression | Multi-Turn Coherence | Creative Quality | Instruction Following | Cost-Effectiveness |
|---|---|---|---|---|---|---|
L3.1-70B-Euryale-v2.2 | 70B | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
L3.1-70B-Hanami-x1 | 70B | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
Cydonia-22B-v1 | 22B | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
MN-Violet-Lotus-12B | 12B | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
MN-12B-Lyra-v4 | 12B | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Chronos-Gold-12B-1.0 | 12B | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Lyra_Gutenbergs-Twilight_Magnum-12B | 12B | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
L3-8B-Lunaris-v1 | 8B | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
Captain_BMO-12B | 12B | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
Rating Key: ⭐⭐⭐⭐⭐ = Excellent, ⭐⭐⭐⭐ = Good, ⭐⭐⭐ = Adequate
Deployment and Integration Guide
API Access Methods
Most recommended models provide API access through the following platforms:
Platform | Focus | Description |
|---|---|---|
Infron | Unified gateway | Unified API gateway supporting multiple model comparisons |
Featherless.ai | Performance | Focused on performance optimization and low-latency inference |
NeuroRouters | Multimodal | Specialized for visual and multimodal setups |
Ragwalla | RAG optimization | RAG-optimized infrastructure |
HuggingFace | Open source | Open-source model repository and inference API |
OpenAI-Compatible Calling Example
from openai import OpenAI client = OpenAI( base_url="https://llm.onerouter.pro/v1", api_key="YOUR_API_KEY", ) completion = client.chat.completions.create( model="sao10k/l3.1-70b-euryale-v2.2", messages=[ { "role": "system", "content": "You are an experienced fantasy adventure guide, skilled at describing vivid scenes and engaging character interactions." }, { "role": "user", "content": "I step into the ancient library, dusty bookshelves stretching endlessly into the distance..." } ], temperature=1.2, top_p=0.95, max_tokens=1000 ) print(completion.choices[0].message.content)
from openai import OpenAI client = OpenAI( base_url="https://llm.onerouter.pro/v1", api_key="YOUR_API_KEY", ) completion = client.chat.completions.create( model="sao10k/l3.1-70b-euryale-v2.2", messages=[ { "role": "system", "content": "You are an experienced fantasy adventure guide, skilled at describing vivid scenes and engaging character interactions." }, { "role": "user", "content": "I step into the ancient library, dusty bookshelves stretching endlessly into the distance..." } ], temperature=1.2, top_p=0.95, max_tokens=1000 ) print(completion.choices[0].message.content)
Local Deployment Options
For users wishing to run models locally:
Recommended Tools:
Ollama: Simplified local model management
LM Studio: GUI-based local inference tool
Text Generation WebUI: Feature-rich web interface
SillyTavern: Frontend specifically optimized for roleplay
Hardware Requirements:
Model Size | Minimum VRAM | Recommended GPU |
|---|---|---|
8B models | 8GB | RTX 3070 or higher |
12B models | 12GB | RTX 3090 or higher |
22B models | 24GB | RTX 4090 or A5000 |
70B models | 48GB | A100 or multi-GPU setup |
Future Trends: 2026-2027 Outlook for Roleplay AI
Technical Evolution Directions
Context windows are pushing beyond 16K toward 100K+ tokens, which means models will soon handle full book-length narratives without losing coherence. We're also seeing multimodal capabilities expand beyond text and images—expect audio, video, and even 3D spatial understanding in the next generation. Latency improvements will enable voice-driven roleplay that feels as natural as talking to another person. And perhaps most importantly, personalized fine-tuning is becoming accessible to non-technical users through simplified tools.
Application Scenario Expansion
Roleplay AI is moving into VR and AR environments for truly immersive experiences. Education sectors are adopting it for professional training and soft skills development. Mental health applications are emerging, offering therapeutic roleplay and emotional support in safe spaces. Enterprise training programs are using it for sales simulations, customer service scenarios, and leadership development exercises.
Community Ecosystem Development
The community is driving innovation through open-source model merging and fine-tuning experiments. Standardization efforts are producing unified benchmarks and best practice guides. Knowledge sharing is thriving through prompt libraries, character card repositories, and scenario template collections that benefit everyone from beginners to advanced users.
Choosing the Best AI Model for Roleplay
The 2026 roleplay AI ecosystem offers unprecedented richness of choice. From lightweight 8B models to powerful 70B multimodal engines, every project can find the right solution.
Our Top Recommendations:
🥇 Overall Best: Sao10K/L3.1-70B-Euryale-v2.2 - Comprehensive leader in creative writing, multi-turn dialogue, and roleplay quality
🥈 Best Value: FallenMerick/MN-Violet-Lotus-12B - King of emotional intelligence at the 12B level with reasonable pricing
🥉 Innovation Pioneer: Sao10K/L3.1-70B-Hanami-x1 - Multimodal capabilities opening future application possibilities
💡 Budget-Friendly: Sao10K/L3-8B-Lunaris-v1 - Small yet powerful with ultimate cost-effectiveness
Whether you're an independent developer, content creator, or enterprise team, this guide should help you make informed choices. As technology continues to evolve, we recommend following model updates and community feedback to continuously optimize your roleplay AI applications.
Get Started Now: Visit Infron to test these models for free and find the solution that best fits your needs.
Frequently Asked Questions
Q1: What's the difference between roleplay AI models and general language models?
A: Roleplay AI models are specifically optimized for conversational coherence, character consistency, emotional expression, and creative narrative. They're typically trained or fine-tuned using specialized datasets containing extensive character dialogues, story plots, and interactive scenarios.
Q2: Are 12B parameter models sufficient for high-quality roleplay?
A: Yes. The 12B models recommended in this article (like MN-Violet-Lotus-12B and MN-12B-Lyra-v4) perform excellently in roleplay tasks, especially after specialized optimization. They offer an excellent balance between quality and resource consumption.
Q3: How can I prevent AI from generating repetitive or out-of-character content?
A: Use the following strategies:
Provide detailed character backgrounds and system prompts
Adjust penalty parameters (frequency, presence, repetition penalties)
Regularly reaffirm key character traits within conversations
Use appropriate temperature values (avoid extremes)
Q4: Are multimodal models (like Hanami-x1) worth the extra cost?
A: If your application scenarios require integrating visual elements (such as visual novels, image-based storytelling, game roleplay), multimodal capabilities are very valuable. Otherwise, text-focused models may be more cost-effective.
Q5: Which is better: open-source models or commercial APIs?
A: It depends on your needs:
Open-source models: Complete control, data privacy, customizability, one-time costs
Commercial APIs: Ease of use, no hardware needed, continuous updates, pay-as-you-go
Q6: How do I evaluate the quality of a roleplay AI model?
A: Key evaluation dimensions include:
Conversational coherence (can it maintain long conversations)
Character consistency (does it maintain character settings)
Emotional intelligence (subtlety of emotional expression)
Creative quality (originality and interest of generated content)
Instruction following (does it output according to prompts)
Related Resources
Infron Model Catalog: https://infron.ai/models
HuggingFace Model Repository: https://huggingface.co/models
SillyTavern Official Website: https://sillytavern.app/
Roleplay AI Community Forum: https://www.reddit.com/r/SillyTavernAI/
The Revolutionary Evolution of AI Models for Roleplay
As artificial intelligence continues to advance through 2026, roleplay AI models have become essential tools in creative writing, interactive storytelling, game development, and conversational systems. These specialized large language models (LLMs) don't just maintain coherent long-form conversations, they understand complex character settings, emotional nuances, and narrative continuity.
This guide evaluates the 10 best roleplay models of 2026, spanning the 8B to 70B spectrum. Whether you are optimizing for edge-device efficiency or flagship multimodal performance, you’ll find the technical breakdown needed to select the optimal engine for your narrative architecture.
Quick Comparison: Top 10 Roleplay AI Models at a Glance
Model | Parameters | Architecture | Context Window | Pricing | Key Feature |
|---|---|---|---|---|---|
L3.1-70B-Euryale-v2.2 | 70B | Llama 3.1 | 16,000 tokens | $3/M tokens | Multi-turn coherence |
L3.1-70B-Hanami-x1 | 70B | Llama 3.1 | 16,000 tokens | $3/M tokens | Text + Vision |
Cydonia-22B-v1 | 22B | - | - | - | Performance-efficiency balance |
MN-Violet-Lotus-12B | 12B | Mistral-NeMo | - | - | EQ score 80.00 |
MN-12B-Lyra-v4 | 12B | Mistral-NeMo | - | - | Direct RL training |
Chronos-Gold-12B-1.0 | 12B | - | - | - | 2,250 token output |
Lyra_Gutenbergs-Twilight_Magnum-12B | 12B | Mistral-NeMo | - | - | Double Back SLERP merge |
L3-8B-Lunaris-v1 | 8B | Llama 3 | 8,200 tokens | $0.04-0.05/M | Lowest cost |
Captain_BMO-12B | 12B | - | - | - | Emerging challenger |
1. Sao10K/L3.1-70B-Euryale-v2.2 - Flagship Multimodal Roleplay Engine
Core Specifications
Parameter Scale: 70B
Architecture Base: Llama 3.1
Context Window: 16,000 tokens
Pricing: $3 per million tokens
Standout Features
L3.1-70B-Euryale-v2.2 represents the pinnacle of Sao10K's work, refined through a two-stage optimization process. The first stage focused on multi-turn conversational instructions, while the second deepened creative writing and roleplay capabilities. During training, the model incorporated human-generated content alongside high-quality data from Claude 3.5 Sonnet and Claude 3 Opus.
Core Advantages:
Enhanced Multi-Turn Coherence: Through specialized multi-turn dialogue datasets, significantly improved context maintenance across extended conversations
Amplified Creative Writing: Contains 55% more roleplay examples (from Gryphe's Sonnet3.5-Charcard-Roleplay dataset) and 40% more creative writing cases
Optimized Instruction Following: Integrated dedicated datasets for system prompt adherence, reasoning, and spatial awareness
Refined Data Quality: Single-turn instruction data replaced with high-quality prompts and responses, extensively filtered to reduce errors
Recommended Configuration: Use Llama 3.1 Instruct format with Euryale 2.1 preset, temperature of 1.2, and min_p of 0.2 for optimal creative and conversational output.
Learn more: Sao10K/L3.1-70B-Euryale-v2.2
2. Sao10K/L3.1-70B-Hanami-x1 - Multimodal Master of Vision and Text Fusion
Core Specifications
Parameter Scale: 70B
Architecture Base: Llama 3.1
Context Window: 16,000 tokens
Multimodal Capability: Text + Visual (image) input
Pricing: $3 per million tokens
Revolutionary Features
L3.1-70B-Hanami-x1 represents the next evolutionary stage of roleplay AI—true multimodal understanding. Released on January 8, 2025, this model can process both text and image inputs simultaneously, creating entirely new possibilities for visual novels, game roleplay, and immersive narrative experiences.
Technical Highlights:
Native Image Processing: Equipped with a specialized vision encoder that understands image content and seamlessly integrates it with text
Extended Context Capability: 16,000 tokens equals approximately 12,000-14,000 words, handling complete research papers or extensive conversation histories
OpenAI-Compatible API: Integrates smoothly into existing workflows
Cross-Platform Availability: Available on NeuroRouters, Infron, Featherless.ai, Ragwalla, and Ridvay
Application Scenarios:
Customer support roleplay with screenshot analysis
Creative content generation with image references
Visual novel-style interactive narratives
Educational roleplay scenarios (combining charts and textual explanations)
Learn more: Sao10K/L3.1-70B-Hanami-x1
3. TheDrummer/Cydonia-22B-v1 - Mid-Size High-Performance Roleplay Specialist
Core Specifications
Parameter Scale: 22B
Developer: TheDrummer
Platform Support: Infron AI
Strategic Positioning
Cydonia-22B-v1 strikes the ideal balance between performance and efficiency. The 22B parameter scale allows it to run on moderate hardware while delivering output quality approaching that of larger models. This makes it the best choice for high-quality roleplay in resource-constrained environments.
Key Advantages:
Cost-Effectiveness: Lower inference costs compared to 70B models
Deployment Flexibility: Can be deployed on mid-tier GPU infrastructure
Performance Balance: Maintains high-quality output while reducing computational demands
Learn more: TheDrummer/Cydonia-22B-v1
4. FallenMerick/MN-Violet-Lotus-12B - King of Emotional Intelligence in Roleplay
Core Specifications
Parameter Scale: 12B
Architecture Base: Mistral-NeMo
Emotional Intelligence Score: 80.00 (Local EQ Benchmark)
Merge Method: Model Stock
The Art of Emotional Expression
MN-Violet-Lotus-12B is a masterpiece crafted by FallenMerick using the Model Stock method, merging four specialized base models:
Epiculous/Violet_Twilight-v0.2
NeverSleep/Lumimaid-v0.2-12B
flammenai/Mahou-1.5-mistral-nemo-12B
Sao10K/MN-12B-Lyra-v4
Unique Advantages:
Exceptional Emotional Intelligence: Excels at understanding and expressing emotional nuances with an EQ score of 80.00
Character Consistency: Maintains diverse character personalities and adapts to various roleplay scenarios
Quality Creative Output: Produces high-quality, imaginative text while avoiding excessive verbosity
Optimized Writing Style: Particularly focuses on balancing coherence and creativity in outputs
Recommended Applications:
Roleplay requiring deep emotional expression
Psychological counseling simulation scenarios
Literary creation and character development
Emotion-driven interactive narratives
Learn more: FallenMerick/MN-Violet-Lotus-12B
5. Sao10K/MN-12B-Lyra-v4 - Reinforcement Learning-Driven Instruction Expert
Core Specifications
Parameter Scale: 12B
Architecture Base: Mistral-NeMo
License: CC-BY-NC-4.0
Supported Formats: ChatML and variants
Innovative Methodology
MN-12B-Lyra-v4 employs a unique reinforcement learning path—training directly on instruction and coherence with the base NeMo model, rather than the traditional SFT-first approach. This innovation has led to better quantization handling and more stable performance.
Technical Innovations:
Direct Reinforcement Learning: Skips traditional SFT stage to directly optimize instruction-following capabilities
Enhanced Tokenizer Configuration: Improved stability and token generation quality
Multi-Format Dialogue Support: Full support for ChatML and its variants
Optimized Sampling Strategy: Recommended temperature range 0.6-1.0, min_p values 0.1-0.2
Best Use Cases:
Structured dialogue interactions
Roleplay requiring precise instruction following
Context-aware conversational scenarios
Enterprise-grade chatbot development
Learn more: Sao10K/MN-12B-Lyra-v4
6. Elinas/Chronos-Gold-12B-1.0 - Long-Form Text Generation Specialist
Core Specifications
Parameter Scale: 12B
Maximum Output Length: 2,250 tokens
Developer Organization: Elina Education
Platform Support: Featherless.ai, Infron
Extended Output Capability
The standout feature of Chronos-Gold-12B-1.0 is its ability to generate up to 2,250 tokens in a single output while maintaining coherence and contextual relevance—a significant advantage for applications requiring detailed, nuanced responses.
Core Capabilities:
Ultra-Long Output Maintenance: Maintains narrative coherence throughout extended generation
Dialogue Optimization: Architecture specifically optimized for dialogue-intensive scenarios
General Chatbot Functionality: Handles diverse conversational topics
Roleplay Adaptability: Suitable for scenarios requiring detailed scene descriptions and complex character interactions
Ideal Applications:
Interactive storytelling (requiring long-form narratives)
Detailed scene description generation
Customer service automation (complex queries)
Educational content creation
Learn more: Elinas/Chronos-Gold-12B-1.0
7. ChaoticNeutrals/Lyra_Gutenbergs-Twilight_Magnum-12B - Literary Style Fusion Model
Core Specifications
Parameter Scale: 12B
Architecture Base: Mistral-NeMo
Merge Method: Double Back SLERP
Supported Formats: Mistral and ChatML
Fusion of Literary DNA
Lyra_Gutenbergs-Twilight_Magnum-12B is a carefully designed fusion model that integrates three original models through the Double Back SLERP merge method:
Anthracite-org/magnum-v2.5-12b-kto
Nbeerbower/Lyra-Gutenberg-mistral-nemo-12B
Epiculous/Violet_Twilight-v0.1
Unique Characteristics:
ShareGPT Format Optimization: Deeply optimized for ShareGPT data format (what the developer calls "ShareGPT Formaxxing")
Dual Format Support: Compatible with both Mistral and ChatML instruction formats
Balanced Literary Style: Fuses literary style characteristics from multiple models, creating a unique writing voice
Community-Driven: An innovative experimental result from the HuggingFace community
Configuration Note: When using SillyTavern with ChatML format, add ["<|im_end|"] to custom stop strings to prevent ChatML EOS token leakage into conversations.
Learn more: ChaoticNeutrals/Lyra_Gutenbergs-Twilight_Magnum-12B
8. Sao10K/L3-8B-Lunaris-v1 - Lightweight Creative and Logic Balancer
Core Specifications
Parameter Scale: 8B
Architecture Base: Llama 3
Context Window: 8.2K tokens
Pricing: Input $0.04/million tokens, Output $0.05/million tokens
Small Yet Powerful
L3-8B-Lunaris-v1 is a versatile general-purpose and roleplay model based on the Llama 3 architecture. Through strategically merging multiple models, it aims to balance creativity with improved logic and general knowledge.
Competitive Advantages:
Ultimate Cost-Effectiveness: Lowest pricing among all recommended models
Fast Response: Smaller parameter scale means faster inference speeds
Balanced Design: Finds optimal equilibrium between creativity, logical reasoning, and knowledge breadth
Easy Deployment: Can run on entry-level GPUs
Suitable Scenarios:
Budget-limited projects
Real-time roleplay applications requiring quick responses
Mobile or edge device deployment
Prototype development and testing phases
Learn more: Sao10K/L3-8B-Lunaris-v1
9. Nitral-AI/Captain_BMO-12B - Emerging Roleplay Challenger
Core Specifications
Parameter Scale: 12B
Developer: Nitral-AI
Platform Support: Infron
Next-Generation Exploration
Captain_BMO-12B represents Nitral-AI's latest exploration in the roleplay AI space. While detailed technical information is limited, the 12B parameter scale positions it in the mid-tier efficient model category, suitable for applications balancing performance and resource consumption.
Strategic Value:
Mid-Range Parameter Scale: Offers a good compromise between quality and efficiency
Community Attention: As an emerging model, closely watched by the AI community
Continuous Evolution: Promising significant improvements in subsequent versions
Learn more: Nitral-AI/Captain_BMO-12B
10. Honorable Mentions: Community Favorites and Rising Stars
Beyond the nine models detailed above, the roleplay AI ecosystem contains many emerging models and experimental projects worth watching:
Fine-Tuned and Quantized Versions
Many base models have community-created GGUF quantized versions that can run under lower hardware requirements. For example, BackyardAI and mradermacher provide multiple quantized versions of MN-Violet-Lotus-12B.
Domain-Specific Models
Some models are optimized for specific types of roleplay, such as fantasy settings, science fiction scenarios, or narratives with particular cultural backgrounds.
How to Choose the Best LLM for roleplay: Decision Framework
1. Selection by Parameter Scale
Parameter Scale | Suitable Scenarios | Recommended Models |
|---|---|---|
8B | Budget-constrained, rapid prototyping, edge deployment | L3-8B-Lunaris-v1 |
12B | Balance performance and cost, medium-complexity tasks | MN-Violet-Lotus-12B, MN-12B-Lyra-v4, Chronos-Gold-12B |
22B | Higher quality needs while controlling costs | Cydonia-22B-v1 |
70B | Highest quality requirements, complex multimodal tasks | L3.1-70B-Euryale-v2.2, L3.1-70B-Hanami-x1 |
2. Selection by Core Capability
Best Emotional Intelligence: MN-Violet-Lotus-12B (EQ score 80.00)
Best Multimodal Capability: L3.1-70B-Hanami-x1 (Text + Vision)
Best Instruction Following: MN-12B-Lyra-v4 (Reinforcement learning optimized)
Longest Output Capability: Chronos-Gold-12B-1.0 (2,250 tokens)
Best Multi-Turn Dialogue: L3.1-70B-Euryale-v2.2 (Multi-turn coherence optimized)
Best Value for Money: L3-8B-Lunaris-v1 ($0.04-0.05/million tokens)
3. Selection by Application Scenario
Game Development:
First choice: L3.1-70B-Hanami-x1 (visual integration)
Alternative: MN-Violet-Lotus-12B (emotional expression)
Creative Writing:
First choice: L3.1-70B-Euryale-v2.2 (creative writing enhanced)
Alternative: Lyra_Gutenbergs-Twilight_Magnum-12B (literary style)
Customer Service:
First choice: MN-12B-Lyra-v4 (instruction following)
Alternative: Chronos-Gold-12B-1.0 (detailed responses)
Budget-Constrained Projects:
First choice: L3-8B-Lunaris-v1 (lowest cost)
Alternative: Any 12B model (moderate cost)
Best Practices for AI Model for Roleplay in 2026
1. Prompt Engineering Optimization
According to the latest 2026 research, high-quality prompt engineering is critical for roleplay effectiveness:
Provide Clear Character Background: Include character history, personality traits, speaking style, and motivations
Set Explicit Scene Context: Describe environment, time period, atmosphere, and relevant background information
Use System Prompts: Leverage the model's system prompt functionality to establish tone and behavioral guidelines
Iterative Refinement: Gradually adjust prompting strategies based on output quality
2. Parameter Tuning Strategies
Different models require different sampling parameter configurations:
Parameter | Value Range | Effect | Best For |
|---|---|---|---|
Temperature | |||
Low | 0.6-0.8 | More consistent, predictable outputs | Structured dialogue |
Medium | 0.8-1.2 | Balance creativity and coherence | General roleplay |
High | 1.2-1.5 | Maximize creativity and diversity | Experimental scenarios |
Min-p | 0.1-0.2 | Controls output filtering | NeMo-based models |
Top-p | 0.9-0.95 | Controls output diversity | All models |
Frequency Penalty | - | Reduces word repetition | Avoiding repetitive vocabulary |
Presence Penalty | - | Encourages new topics | Introducing variety |
Repetition Penalty | - | Avoids sentence pattern repetition | Preventing monotonous output |
3. Context Management Techniques
Effectively Using Context Windows:
Regularly summarize long conversations to compress context
Prioritize retention of key information (character settings, important plot points)
For ultra-long scenarios, consider segmented processing
RAG Integration:
Use Retrieval-Augmented Generation (RAG) to extend model knowledge
Integrate character cards, world settings, and reference materials
Retrieve relevant context in real-time rather than loading everything
4. Multimodal Application Strategies
For models supporting visual input (like L3.1-70B-Hanami-x1):
Image Preprocessing: Ensure images are clear with appropriate resolution
Text-Image Alignment: Explicitly reference image content in prompts
Progressive Multimodality: Establish text context first, then introduce visual elements
5. Safety and Ethical Considerations
Content Filtering: Implement appropriate output review mechanisms
User Privacy: Don't share sensitive personal information with AI
Boundary Setting: Clearly communicate the virtual nature of AI roleplay
Copyright Awareness: Ensure generated content complies with copyright laws
Performance Benchmarking: 2026 AI Model for Roleplay Comparison
Model Name | Parameter Scale | Emotional Expression | Multi-Turn Coherence | Creative Quality | Instruction Following | Cost-Effectiveness |
|---|---|---|---|---|---|---|
L3.1-70B-Euryale-v2.2 | 70B | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
L3.1-70B-Hanami-x1 | 70B | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
Cydonia-22B-v1 | 22B | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
MN-Violet-Lotus-12B | 12B | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
MN-12B-Lyra-v4 | 12B | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Chronos-Gold-12B-1.0 | 12B | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
Lyra_Gutenbergs-Twilight_Magnum-12B | 12B | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
L3-8B-Lunaris-v1 | 8B | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
Captain_BMO-12B | 12B | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
Rating Key: ⭐⭐⭐⭐⭐ = Excellent, ⭐⭐⭐⭐ = Good, ⭐⭐⭐ = Adequate
Deployment and Integration Guide
API Access Methods
Most recommended models provide API access through the following platforms:
Platform | Focus | Description |
|---|---|---|
Infron | Unified gateway | Unified API gateway supporting multiple model comparisons |
Featherless.ai | Performance | Focused on performance optimization and low-latency inference |
NeuroRouters | Multimodal | Specialized for visual and multimodal setups |
Ragwalla | RAG optimization | RAG-optimized infrastructure |
HuggingFace | Open source | Open-source model repository and inference API |
OpenAI-Compatible Calling Example
from openai import OpenAI client = OpenAI( base_url="https://llm.onerouter.pro/v1", api_key="YOUR_API_KEY", ) completion = client.chat.completions.create( model="sao10k/l3.1-70b-euryale-v2.2", messages=[ { "role": "system", "content": "You are an experienced fantasy adventure guide, skilled at describing vivid scenes and engaging character interactions." }, { "role": "user", "content": "I step into the ancient library, dusty bookshelves stretching endlessly into the distance..." } ], temperature=1.2, top_p=0.95, max_tokens=1000 ) print(completion.choices[0].message.content)
Local Deployment Options
For users wishing to run models locally:
Recommended Tools:
Ollama: Simplified local model management
LM Studio: GUI-based local inference tool
Text Generation WebUI: Feature-rich web interface
SillyTavern: Frontend specifically optimized for roleplay
Hardware Requirements:
Model Size | Minimum VRAM | Recommended GPU |
|---|---|---|
8B models | 8GB | RTX 3070 or higher |
12B models | 12GB | RTX 3090 or higher |
22B models | 24GB | RTX 4090 or A5000 |
70B models | 48GB | A100 or multi-GPU setup |
Future Trends: 2026-2027 Outlook for Roleplay AI
Technical Evolution Directions
Context windows are pushing beyond 16K toward 100K+ tokens, which means models will soon handle full book-length narratives without losing coherence. We're also seeing multimodal capabilities expand beyond text and images—expect audio, video, and even 3D spatial understanding in the next generation. Latency improvements will enable voice-driven roleplay that feels as natural as talking to another person. And perhaps most importantly, personalized fine-tuning is becoming accessible to non-technical users through simplified tools.
Application Scenario Expansion
Roleplay AI is moving into VR and AR environments for truly immersive experiences. Education sectors are adopting it for professional training and soft skills development. Mental health applications are emerging, offering therapeutic roleplay and emotional support in safe spaces. Enterprise training programs are using it for sales simulations, customer service scenarios, and leadership development exercises.
Community Ecosystem Development
The community is driving innovation through open-source model merging and fine-tuning experiments. Standardization efforts are producing unified benchmarks and best practice guides. Knowledge sharing is thriving through prompt libraries, character card repositories, and scenario template collections that benefit everyone from beginners to advanced users.
Choosing the Best AI Model for Roleplay
The 2026 roleplay AI ecosystem offers unprecedented richness of choice. From lightweight 8B models to powerful 70B multimodal engines, every project can find the right solution.
Our Top Recommendations:
🥇 Overall Best: Sao10K/L3.1-70B-Euryale-v2.2 - Comprehensive leader in creative writing, multi-turn dialogue, and roleplay quality
🥈 Best Value: FallenMerick/MN-Violet-Lotus-12B - King of emotional intelligence at the 12B level with reasonable pricing
🥉 Innovation Pioneer: Sao10K/L3.1-70B-Hanami-x1 - Multimodal capabilities opening future application possibilities
💡 Budget-Friendly: Sao10K/L3-8B-Lunaris-v1 - Small yet powerful with ultimate cost-effectiveness
Whether you're an independent developer, content creator, or enterprise team, this guide should help you make informed choices. As technology continues to evolve, we recommend following model updates and community feedback to continuously optimize your roleplay AI applications.
Get Started Now: Visit Infron to test these models for free and find the solution that best fits your needs.
Frequently Asked Questions
Q1: What's the difference between roleplay AI models and general language models?
A: Roleplay AI models are specifically optimized for conversational coherence, character consistency, emotional expression, and creative narrative. They're typically trained or fine-tuned using specialized datasets containing extensive character dialogues, story plots, and interactive scenarios.
Q2: Are 12B parameter models sufficient for high-quality roleplay?
A: Yes. The 12B models recommended in this article (like MN-Violet-Lotus-12B and MN-12B-Lyra-v4) perform excellently in roleplay tasks, especially after specialized optimization. They offer an excellent balance between quality and resource consumption.
Q3: How can I prevent AI from generating repetitive or out-of-character content?
A: Use the following strategies:
Provide detailed character backgrounds and system prompts
Adjust penalty parameters (frequency, presence, repetition penalties)
Regularly reaffirm key character traits within conversations
Use appropriate temperature values (avoid extremes)
Q4: Are multimodal models (like Hanami-x1) worth the extra cost?
A: If your application scenarios require integrating visual elements (such as visual novels, image-based storytelling, game roleplay), multimodal capabilities are very valuable. Otherwise, text-focused models may be more cost-effective.
Q5: Which is better: open-source models or commercial APIs?
A: It depends on your needs:
Open-source models: Complete control, data privacy, customizability, one-time costs
Commercial APIs: Ease of use, no hardware needed, continuous updates, pay-as-you-go
Q6: How do I evaluate the quality of a roleplay AI model?
A: Key evaluation dimensions include:
Conversational coherence (can it maintain long conversations)
Character consistency (does it maintain character settings)
Emotional intelligence (subtlety of emotional expression)
Creative quality (originality and interest of generated content)
Instruction following (does it output according to prompts)
Related Resources
Infron Model Catalog: https://infron.ai/models
HuggingFace Model Repository: https://huggingface.co/models
SillyTavern Official Website: https://sillytavern.app/
Roleplay AI Community Forum: https://www.reddit.com/r/SillyTavernAI/
More Articles

LLM Tracing
LLM Tracing & Observability: A Guide to Debugging AI Apps
LLM Tracing
LLM Tracing & Observability: A Guide to Debugging AI Apps

LLM Hallucination Detection
LLM Hallucination Detection Methods: 5 Ways to Catch AI Errors
LLM Hallucination Detection
LLM Hallucination Detection Methods: 5 Ways to Catch AI Errors

AI Image models
5 Best AI Image Generation Models in 2026
AI Image models
5 Best AI Image Generation Models in 2026
Less orchestration.
More innovation.
Seamlessly integrate Infron with just a few lines of code and unlock unlimited AI power.
Less orchestration.
More innovation.
Seamlessly integrate Infron with just a few lines of code and unlock unlimited AI power.
Less orchestration.
More innovation.
Seamlessly integrate Infron with just a few lines of code and unlock unlimited AI power.