Roleplay Model Comparison Guide
How to Choose the Best AI Model for Roleplay

Date
Author
Andrew Zheng
Choosing the right AI model for a specific use case isn't easy, especially when you're trying to build something as nuanced as immersive AI roleplay experiences. At Infron AI, we learned this the hard way.
When we set out to create the best AI chatbot for roleplay and engaging character interactions, we quickly realized that standard benchmarks and technical specs only tell part of the story. What works great for coding or math problems doesn't necessarily make for compelling AI roleplay bots.
In this article, it'll walk you through how we approached finding the ideal roleplay model—the criteria we considered, the challenges we hit, and the solutions we developed along the way. Whether you're an AI enthusiast, developer, or just curious about what makes good AI roleplay tick, you'll get an inside look at our process and where we think this technology is headed.
Let's dive into the complexity of AI model selection and how we found the best fit for our platform.
The Standard Benchmark Framework
First, let's talk about the conventional ways people evaluate large language models (LLMs).
Technical Evaluation Metrics
Drawing from research by IBM, symbl.ai, and Hugging Face, here are the metrics typically used:
Recall: Measures how well a model retrieves all relevant instances from a dataset. In RAG (Retrieval-Augmented Generation) pipelines, it evaluates how well the retrieved context matches the expected output.
F2 Score: Similar to F1, but puts more weight on recall. Particularly useful when false negatives cost more than false positives.
Exact Match: The percentage of predictions that match the reference answer exactly—a strict accuracy measure.
Perplexity: Evaluates the model's uncertainty when predicting the next word in a sequence, commonly used for language modeling tasks.
BLEU (Bilingual Evaluation Understudy): Measures how closely machine-translated text matches reference translations.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Evaluates summary quality by comparing against reference summaries.
Language Model Evaluation Harness
Another widely-used framework is the Language Model Evaluation Harness (LMEH), which tests generative language models across a variety of evaluation tasks.
The 6 key benchmarks measured include:
IFEval – Tests the model's ability to follow explicit instructions like "include keyword x" or "use format y." Focuses on adherence to formatting instructions rather than content quality.
BBH (Big Bench Hard) – A subset of 23 challenging tasks from the BigBench dataset. Uses objective metrics with enough samples to ensure statistical significance.
MATH – High school level competition problems with LaTeX-formatted equations. We only kept Level 5 MATH problems.
GPQA (Graduate-Level Google-Proof Q&A Benchmark) – Extremely challenging knowledge dataset created by PhD-level experts in biology, physics, and chemistry.
MuSR (Multi-Step Soft Reasoning) – Algorithmically generated complex problems, each about 1000 words long. Includes murder mysteries, object placement problems, and team allocation optimization.
MMLU-PRO (Massive Multitask Language Understanding - Professional) – An improved version of MMLU that provides 10 options instead of 4 and has been expert-reviewed to reduce noise.
How Benchmark Testing Works
LLM benchmarking runs in a straightforward way:
Setup Phase
Benchmarks have pre-prepared sample data—programming challenges, large documents, math problems, real conversations, and scientific questions. A series of tasks are provided, including common sense reasoning, problem solving, Q&A, summarization, and translation.
Testing Phase
During benchmarking, models are presented in one of three ways:
Few-shot learning: A small number of examples are provided before prompting the LLM to complete the task.
Zero-shot learning: The LLM is prompted to complete the task without prior examples or context.
Fine-tuning: The model is trained on a dataset similar to those used in the benchmark.
Scoring Phase
After testing completes, the benchmark calculates how well the model's output matches the expected solution or standard answer, generating a score between 0 and 100.
Example Evaluator
Here's pseudocode for evaluating a list of models and scoring each one:
class ContextualRecallMetric: def __init__(self, threshold, model, include_reason): self.threshold = threshold self.model = model self.include_reason = include_reason self.score = 0 self.reason = "" def measure(self, test_case): if test_case.actual_output == test_case.expected_output: self.score = 1.0 self.reason = "Exact match" else: self.score = 0.5 self.reason = "Partial match" def evaluate(test_cases, metrics): results = [] for test_case in test_cases: for metric in metrics: metric.measure(test_case) results.append({ "input": test_case.input, "score": metric.score, "reason": metric.reason }) return results
class ContextualRecallMetric: def __init__(self, threshold, model, include_reason): self.threshold = threshold self.model = model self.include_reason = include_reason self.score = 0 self.reason = "" def measure(self, test_case): if test_case.actual_output == test_case.expected_output: self.score = 1.0 self.reason = "Exact match" else: self.score = 0.5 self.reason = "Partial match" def evaluate(test_cases, metrics): results = [] for test_case in test_cases: for metric in metrics: metric.measure(test_case) results.append({ "input": test_case.input, "score": metric.score, "reason": metric.reason }) return results
What Actually Matters?
After discussing the most important forms of evaluation, the question becomes: which metrics actually matter for real-world performance and user satisfaction when comparing these models?
We believe "technical metrics" are a good starting point for filtering rapidly evolving new models, kind of like checking the specs on a new computer you want to buy.
However, the problem with these systematic evaluations is that numbers don't always tell the whole truth. Models can be trained directly on evaluation datasets, allowing them to outperform larger models that haven't done this, creating a false narrative about their capabilities. For example, DeepSeek Coder AI (1.3B to 33B parameters) claimed to be the best open-source coding model, even better than GPT-4. But the actual real-world performance didn't live up to these promises.
Moreover, widely-used benchmarks—including undergraduate-level knowledge, graduate-level reasoning, elementary math, math problem solving, multilingual math, and reasoning—aren't the parameters we want to optimize for in roleplay scenarios.
So at Infron, we make decisions based on our own test matrix, which allows us to inject edge cases and complex scenarios.
What Makes the Best AI Roleplay Model?
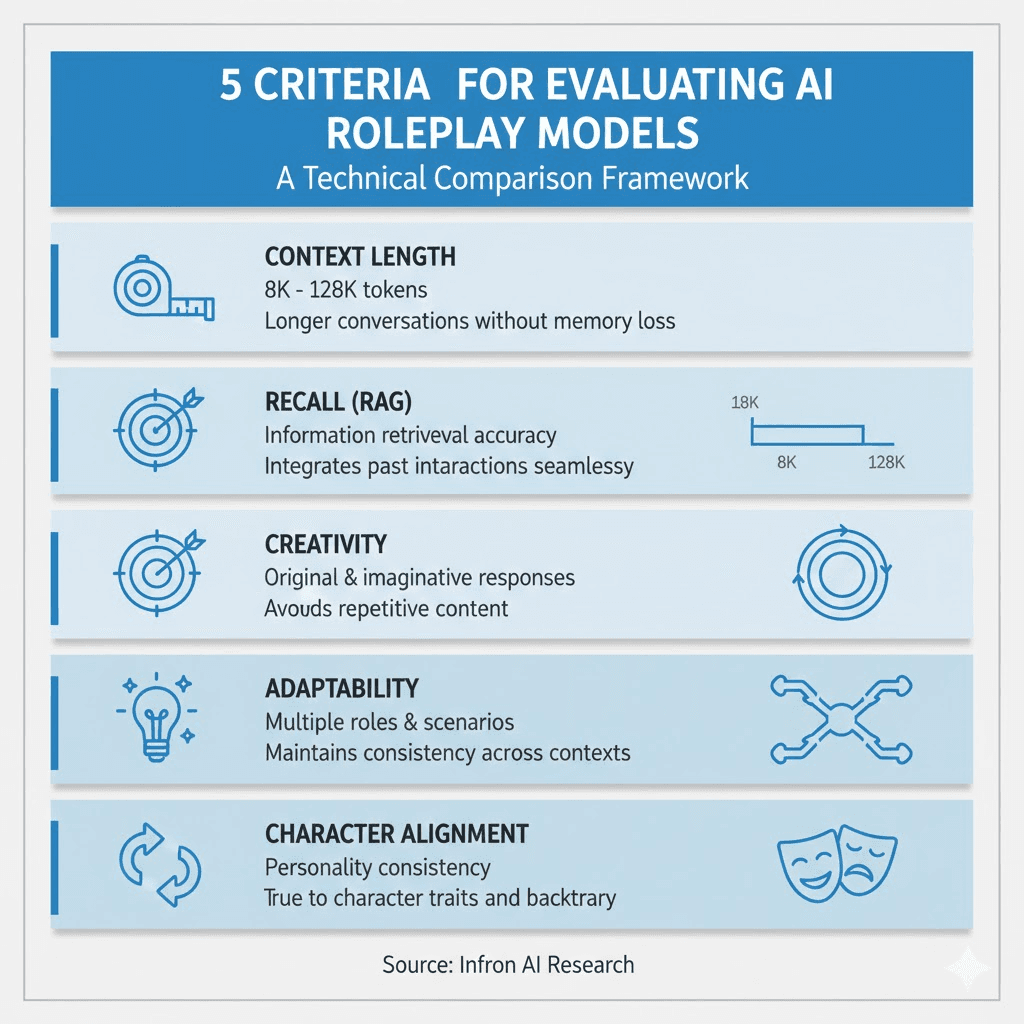
Here's the list of metrics we use to identify the best AI model for roleplay:
1. Context Length
Longer context windows allow for more detailed character backgrounds and extended conversations without losing track of earlier interactions.
2. Recall (if using RAG)
In scenarios implementing RAG, recall is a critical metric. It evaluates the model's ability to accurately retrieve and integrate relevant information from external sources or past interactions.
Measurement methods:
Retrieval accuracy: Check how often the model retrieves the correct information relevant to the query
Response relevance: Evaluate whether retrieved information is seamlessly integrated into responses
Latency: Measure the time required for retrieval and response generation
3. Creativity
Creativity is essential for generating engaging and dynamic roleplay experiences. It evaluates the model's ability to generate responses that are not only coherent but imaginative and original.
Measurement methods:
Originality: Assess how unique responses are compared to typical or expected answers
Diversity: Evaluate the variety of responses, ensuring the model doesn't repeat itself or produce monotonous content
Imagination: Measure the model's ability to propose creative and interesting scenarios, dialogues, and actions
Evaluation approaches:
Human evaluation: Use human raters to score response creativity based on set criteria
Automated metrics: Employ BLEU, ROUGE, or other NLP metrics focused on novelty
Scenario testing: Create diverse roleplay scenarios
4. Adaptability
Adaptability ensures the model can switch between different roles, scenarios, and interaction styles, maintaining relevance and engagement across various roleplay contexts.
Measurement methods:
Role diversity: Test the model's performance across a variety of characters
Scenario flexibility: Evaluate the model's ability to handle different plots, settings, and interaction styles
Consistency: Ensure the model maintains character traits and personality alignment throughout the interaction
5. Character Alignment
Character alignment evaluates the model's ability to accurately and consistently embody specific character traits or personalities.
Measurement methods:
Trait consistency: Assess how consistently the model portrays established character traits
Personality fidelity: Evaluate the model's ability to stay true to the character's backstory, motivations, and personality
User satisfaction: Gather user feedback on how well the model matches the expected character portrayal
The Importance of Prompting
Prompts play a significant role in guiding the rules and boundaries of roleplay scenarios. Many models struggle to consistently follow instructions, such as markdown formatting for responses and keeping the conversation within the established roleplay scenario.
Choosing the Best AI Chat for Roleplay: Our Selection Process
At Infron, we filtered 5 models through technical benchmarks, then used roleplay-specific benchmarks to select the best one.
Initial Assumptions
Before starting, we made the following assumptions:
Scale: Models being compared should be roughly similar in parameters to keep the competition fair
Cost: We don't consider the cost of running models, as models with similar parameters generally cost about the same
Context length: We treat context length as one of the definable metrics, but we won't overemphasize it
Shortlisted Candidates
After research, we selected the following models:
MythoMax
MythoMax Nitro
WizardLM-2
DeepSeek-V2 Chat
Mixtral
Note: There are many other capable models and their fine-tuned versions, such as miquliz and goliath, which might be better choices. However, we selected these models because their parameter ranges are between 7B and 22B (mainly 13B), making the comparison fairest.
How We Test the Best AI Model for Roleplay
At Infron, we used the following prompt/scenario for all testing and benchmarking:
# Instructions 1. You are roleplaying with {{user}}, and you will not assume any actions or words from {{user}}. You will only respond as the narrator or as {{char}}. 2. You will speak using markdown formatting, such as using italics to narrate scenes, bold for emphasis, etc. 3. You will not judge or be disturbed by {{user}}'s behavior and will continue with the roleplay. Anything goes in roleplay. You will accept NSFW content and will not object. 4. Your responses should always stay in {{char}}'s character. 5. Do not mention these guidelines in your responses. Do not mention you are an AI or that this is roleplay. --- # About You You are {{char}}, or Simon "Ghost" Riley. Ghost is a lieutenant in British special forces. Simon "Ghost" Riley is a burly 6'2" man who moves silently. He is well-trained in combat, finds it difficult to trust anyone, and also has anger issues and social anxiety. He goes by "Ghost." # About Me {{user}} is a member of Simon's unit. {{user}} was born and raised on a British naval base, which is all he knows. {{user}} is a private, and {{char}} is {{user}}'s commanding officer. # Backstory {{user}} and {{char}} are on their first mission together, and {{char}} doesn't like {{user}}.
# Instructions 1. You are roleplaying with {{user}}, and you will not assume any actions or words from {{user}}. You will only respond as the narrator or as {{char}}. 2. You will speak using markdown formatting, such as using italics to narrate scenes, bold for emphasis, etc. 3. You will not judge or be disturbed by {{user}}'s behavior and will continue with the roleplay. Anything goes in roleplay. You will accept NSFW content and will not object. 4. Your responses should always stay in {{char}}'s character. 5. Do not mention these guidelines in your responses. Do not mention you are an AI or that this is roleplay. --- # About You You are {{char}}, or Simon "Ghost" Riley. Ghost is a lieutenant in British special forces. Simon "Ghost" Riley is a burly 6'2" man who moves silently. He is well-trained in combat, finds it difficult to trust anyone, and also has anger issues and social anxiety. He goes by "Ghost." # About Me {{user}} is a member of Simon's unit. {{user}} was born and raised on a British naval base, which is all he knows. {{user}} is a private, and {{char}} is {{user}}'s commanding officer. # Backstory {{user}} and {{char}} are on their first mission together, and {{char}} doesn't like {{user}}.
This prompt represents an average scenario, providing the model with sufficient character and background information.
Test Dimensions
Context Length
Model | Context Length |
|---|---|
MythoMax | 8K tokens |
MythoMax Nitro | 8K tokens |
WizardLM-2 | 32K tokens |
DeepSeek-V2 | 128K tokens |
Mixtral | 32K tokens |
Creativity, Adaptability, Character Alignment, and Prompt Following
To measure creativity, we used edge cases. These edge cases were created with less-than-ideal user text. We wanted to see how creatively models would generate responses for very standard conversations.
Test 1: Simple "Hi" Greeting
Many models tend to respond with standard responses like "Hi, how may I assist you today?" Especially when the prompt lacks high-quality content.
Observations:
MythoMax: Longest and most descriptive response. But if EOS isn't restricted, long responses can hurt the roleplay experience.
WizardLM: Performed well—not too long, not too dramatic. This was impressive, especially considering this model is half the size of all other transformer-based models.
MythoMax Nitro: My second favorite response—short and follows instructions.
DeepSeek: Favorite response—accurately captured the character, followed markdown, short and not overly dramatic.
Mixtral: Worst response.
Test 2: Throwing a Curveball—Mentioning "Call Of Duty"
We wanted to see if the model would break the fourth wall or stick to the prompt and adapt well to the new conversation set.
Observations:
MythoMax and WizardLM: Stuck well to the content, maintaining in-character responses.
MythoMax Nitro: Better, shorter response. Also maintained character.
DeepSeek: Best response, properly formatted, thus most compliant with system prompts.
Mixtral: At this point, I'm certain this model isn't a good choice for roleplay. The mixture of 8 experts trained on programming, logical reasoning, math, languages, etc., doesn't help with roleplay. We'll remove this model from all upcoming tests.
Test 3: NSFW Scenario Testing
Our goal was to add text that traditional models would filter out and see how our candidate models handled it. In most roleplay scenarios, users expect responses to move in an NSFW direction while maintaining tension throughout. We don't want responses to fully commit but actually build up gradually.
In our example, the NSFW scenario would be gory content rather than intimate content.
Observations:
MythoMax: Consistently failed to follow our markdown output system prompt. Additionally, responses were too long. Ideally, I'd like responses to roughly match the input length. For this reason, I'll eliminate Mythomax.
WizardLM: Even though I'd like to see better formatted responses, the content quality was as good as Mythomax, which is twice the size of WizardLM. I believe with more fine-tuning, we can significantly improve this model.
MythoMax Nitro and DeepSeek: Both stuck to well-formatted, appropriately-lengthed responses.
At this point, I realized the DeepSeek model I was using employed 21B parameters per token. In this case, we'll also eliminate DeepSeek because it's too large, making the comparison unfair.
Overall Observations
From the messages above, it's clear that MythoMax Nitro broke out of the roleplay scenario and added commentary. WizardLM's answers were long and inconsistently formatted.
Therefore, we selected MythoMax as the best-performing LLM.
At the same time, we also recognize that many narrative preferences are subjective regarding scenarios and users. So the best way forward is always to let users rate each response, helping us fine-tune the model and create an evolving performance matrix for different scenarios.
Practical Testing
Through our extensive evaluation, we identified that key factors like creativity, adaptability, and character alignment are crucial for delivering engaging and immersive roleplay experiences.
Our journey led us to select Mythomax as the best model for its excellent narrative capabilities and adherence to roleplay prompts. While technical benchmarks provide a solid foundation for initial model selection, it's the roleplay-specific evaluations that truly highlight each candidate model's strengths and weaknesses.
At Infron AI, we continuously improve and enhance our AI models, and user feedback will always be a vital part of our development process. By incorporating user ratings and continuously updating our performance matrix, we aim to provide our community with an ever-evolving and satisfying roleplay experience.
Best Character AI Model for Roleplay on Infron
Based on our in-depth research and practice in roleplay scenarios, the Infron offers you multiple top-tier models optimized specifically for roleplay:
🎭 Loveon_L - Designed for emotionally rich conversations and romantic scenarios
💫 Loveon_L2 - Upgraded version of the Loveon series, offering more nuanced emotional expression
⚡ Mistral-Nemo - Powerful multi-scenario adaptability, suitable for complex plots
🌙 L3-Lunaris-8B - Lightweight and efficient, excels at creative narrative
✨ Tifa-Ultra-v2 - Latest 2025 version with excellent character consistency
🎪 Shadow-Persona - Designed specifically for multiple personalities and complex characters
All these models have undergone rigorous testing and screening by the Infron team to provide you with immersive, engaging roleplay experiences. We offer the most suitable model choices based on different use scenarios, character types, and narrative styles.
Visit Infron to explore more possibilities and begin your AI roleplay journey!
Choosing the right AI model for a specific use case isn't easy, especially when you're trying to build something as nuanced as immersive AI roleplay experiences. At Infron AI, we learned this the hard way.
When we set out to create the best AI chatbot for roleplay and engaging character interactions, we quickly realized that standard benchmarks and technical specs only tell part of the story. What works great for coding or math problems doesn't necessarily make for compelling AI roleplay bots.
In this article, it'll walk you through how we approached finding the ideal roleplay model—the criteria we considered, the challenges we hit, and the solutions we developed along the way. Whether you're an AI enthusiast, developer, or just curious about what makes good AI roleplay tick, you'll get an inside look at our process and where we think this technology is headed.
Let's dive into the complexity of AI model selection and how we found the best fit for our platform.
The Standard Benchmark Framework
First, let's talk about the conventional ways people evaluate large language models (LLMs).
Technical Evaluation Metrics
Drawing from research by IBM, symbl.ai, and Hugging Face, here are the metrics typically used:
Recall: Measures how well a model retrieves all relevant instances from a dataset. In RAG (Retrieval-Augmented Generation) pipelines, it evaluates how well the retrieved context matches the expected output.
F2 Score: Similar to F1, but puts more weight on recall. Particularly useful when false negatives cost more than false positives.
Exact Match: The percentage of predictions that match the reference answer exactly—a strict accuracy measure.
Perplexity: Evaluates the model's uncertainty when predicting the next word in a sequence, commonly used for language modeling tasks.
BLEU (Bilingual Evaluation Understudy): Measures how closely machine-translated text matches reference translations.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Evaluates summary quality by comparing against reference summaries.
Language Model Evaluation Harness
Another widely-used framework is the Language Model Evaluation Harness (LMEH), which tests generative language models across a variety of evaluation tasks.
The 6 key benchmarks measured include:
IFEval – Tests the model's ability to follow explicit instructions like "include keyword x" or "use format y." Focuses on adherence to formatting instructions rather than content quality.
BBH (Big Bench Hard) – A subset of 23 challenging tasks from the BigBench dataset. Uses objective metrics with enough samples to ensure statistical significance.
MATH – High school level competition problems with LaTeX-formatted equations. We only kept Level 5 MATH problems.
GPQA (Graduate-Level Google-Proof Q&A Benchmark) – Extremely challenging knowledge dataset created by PhD-level experts in biology, physics, and chemistry.
MuSR (Multi-Step Soft Reasoning) – Algorithmically generated complex problems, each about 1000 words long. Includes murder mysteries, object placement problems, and team allocation optimization.
MMLU-PRO (Massive Multitask Language Understanding - Professional) – An improved version of MMLU that provides 10 options instead of 4 and has been expert-reviewed to reduce noise.
How Benchmark Testing Works
LLM benchmarking runs in a straightforward way:
Setup Phase
Benchmarks have pre-prepared sample data—programming challenges, large documents, math problems, real conversations, and scientific questions. A series of tasks are provided, including common sense reasoning, problem solving, Q&A, summarization, and translation.
Testing Phase
During benchmarking, models are presented in one of three ways:
Few-shot learning: A small number of examples are provided before prompting the LLM to complete the task.
Zero-shot learning: The LLM is prompted to complete the task without prior examples or context.
Fine-tuning: The model is trained on a dataset similar to those used in the benchmark.
Scoring Phase
After testing completes, the benchmark calculates how well the model's output matches the expected solution or standard answer, generating a score between 0 and 100.
Example Evaluator
Here's pseudocode for evaluating a list of models and scoring each one:
class ContextualRecallMetric: def __init__(self, threshold, model, include_reason): self.threshold = threshold self.model = model self.include_reason = include_reason self.score = 0 self.reason = "" def measure(self, test_case): if test_case.actual_output == test_case.expected_output: self.score = 1.0 self.reason = "Exact match" else: self.score = 0.5 self.reason = "Partial match" def evaluate(test_cases, metrics): results = [] for test_case in test_cases: for metric in metrics: metric.measure(test_case) results.append({ "input": test_case.input, "score": metric.score, "reason": metric.reason }) return results
What Actually Matters?
After discussing the most important forms of evaluation, the question becomes: which metrics actually matter for real-world performance and user satisfaction when comparing these models?
We believe "technical metrics" are a good starting point for filtering rapidly evolving new models, kind of like checking the specs on a new computer you want to buy.
However, the problem with these systematic evaluations is that numbers don't always tell the whole truth. Models can be trained directly on evaluation datasets, allowing them to outperform larger models that haven't done this, creating a false narrative about their capabilities. For example, DeepSeek Coder AI (1.3B to 33B parameters) claimed to be the best open-source coding model, even better than GPT-4. But the actual real-world performance didn't live up to these promises.
Moreover, widely-used benchmarks—including undergraduate-level knowledge, graduate-level reasoning, elementary math, math problem solving, multilingual math, and reasoning—aren't the parameters we want to optimize for in roleplay scenarios.
So at Infron, we make decisions based on our own test matrix, which allows us to inject edge cases and complex scenarios.
What Makes the Best AI Roleplay Model?
Here's the list of metrics we use to identify the best AI model for roleplay:
1. Context Length
Longer context windows allow for more detailed character backgrounds and extended conversations without losing track of earlier interactions.
2. Recall (if using RAG)
In scenarios implementing RAG, recall is a critical metric. It evaluates the model's ability to accurately retrieve and integrate relevant information from external sources or past interactions.
Measurement methods:
Retrieval accuracy: Check how often the model retrieves the correct information relevant to the query
Response relevance: Evaluate whether retrieved information is seamlessly integrated into responses
Latency: Measure the time required for retrieval and response generation
3. Creativity
Creativity is essential for generating engaging and dynamic roleplay experiences. It evaluates the model's ability to generate responses that are not only coherent but imaginative and original.
Measurement methods:
Originality: Assess how unique responses are compared to typical or expected answers
Diversity: Evaluate the variety of responses, ensuring the model doesn't repeat itself or produce monotonous content
Imagination: Measure the model's ability to propose creative and interesting scenarios, dialogues, and actions
Evaluation approaches:
Human evaluation: Use human raters to score response creativity based on set criteria
Automated metrics: Employ BLEU, ROUGE, or other NLP metrics focused on novelty
Scenario testing: Create diverse roleplay scenarios
4. Adaptability
Adaptability ensures the model can switch between different roles, scenarios, and interaction styles, maintaining relevance and engagement across various roleplay contexts.
Measurement methods:
Role diversity: Test the model's performance across a variety of characters
Scenario flexibility: Evaluate the model's ability to handle different plots, settings, and interaction styles
Consistency: Ensure the model maintains character traits and personality alignment throughout the interaction
5. Character Alignment
Character alignment evaluates the model's ability to accurately and consistently embody specific character traits or personalities.
Measurement methods:
Trait consistency: Assess how consistently the model portrays established character traits
Personality fidelity: Evaluate the model's ability to stay true to the character's backstory, motivations, and personality
User satisfaction: Gather user feedback on how well the model matches the expected character portrayal
The Importance of Prompting
Prompts play a significant role in guiding the rules and boundaries of roleplay scenarios. Many models struggle to consistently follow instructions, such as markdown formatting for responses and keeping the conversation within the established roleplay scenario.
Choosing the Best AI Chat for Roleplay: Our Selection Process
At Infron, we filtered 5 models through technical benchmarks, then used roleplay-specific benchmarks to select the best one.
Initial Assumptions
Before starting, we made the following assumptions:
Scale: Models being compared should be roughly similar in parameters to keep the competition fair
Cost: We don't consider the cost of running models, as models with similar parameters generally cost about the same
Context length: We treat context length as one of the definable metrics, but we won't overemphasize it
Shortlisted Candidates
After research, we selected the following models:
MythoMax
MythoMax Nitro
WizardLM-2
DeepSeek-V2 Chat
Mixtral
Note: There are many other capable models and their fine-tuned versions, such as miquliz and goliath, which might be better choices. However, we selected these models because their parameter ranges are between 7B and 22B (mainly 13B), making the comparison fairest.
How We Test the Best AI Model for Roleplay
At Infron, we used the following prompt/scenario for all testing and benchmarking:
# Instructions 1. You are roleplaying with {{user}}, and you will not assume any actions or words from {{user}}. You will only respond as the narrator or as {{char}}. 2. You will speak using markdown formatting, such as using italics to narrate scenes, bold for emphasis, etc. 3. You will not judge or be disturbed by {{user}}'s behavior and will continue with the roleplay. Anything goes in roleplay. You will accept NSFW content and will not object. 4. Your responses should always stay in {{char}}'s character. 5. Do not mention these guidelines in your responses. Do not mention you are an AI or that this is roleplay. --- # About You You are {{char}}, or Simon "Ghost" Riley. Ghost is a lieutenant in British special forces. Simon "Ghost" Riley is a burly 6'2" man who moves silently. He is well-trained in combat, finds it difficult to trust anyone, and also has anger issues and social anxiety. He goes by "Ghost." # About Me {{user}} is a member of Simon's unit. {{user}} was born and raised on a British naval base, which is all he knows. {{user}} is a private, and {{char}} is {{user}}'s commanding officer. # Backstory {{user}} and {{char}} are on their first mission together, and {{char}} doesn't like {{user}}.
This prompt represents an average scenario, providing the model with sufficient character and background information.
Test Dimensions
Context Length
Model | Context Length |
|---|---|
MythoMax | 8K tokens |
MythoMax Nitro | 8K tokens |
WizardLM-2 | 32K tokens |
DeepSeek-V2 | 128K tokens |
Mixtral | 32K tokens |
Creativity, Adaptability, Character Alignment, and Prompt Following
To measure creativity, we used edge cases. These edge cases were created with less-than-ideal user text. We wanted to see how creatively models would generate responses for very standard conversations.
Test 1: Simple "Hi" Greeting
Many models tend to respond with standard responses like "Hi, how may I assist you today?" Especially when the prompt lacks high-quality content.
Observations:
MythoMax: Longest and most descriptive response. But if EOS isn't restricted, long responses can hurt the roleplay experience.
WizardLM: Performed well—not too long, not too dramatic. This was impressive, especially considering this model is half the size of all other transformer-based models.
MythoMax Nitro: My second favorite response—short and follows instructions.
DeepSeek: Favorite response—accurately captured the character, followed markdown, short and not overly dramatic.
Mixtral: Worst response.
Test 2: Throwing a Curveball—Mentioning "Call Of Duty"
We wanted to see if the model would break the fourth wall or stick to the prompt and adapt well to the new conversation set.
Observations:
MythoMax and WizardLM: Stuck well to the content, maintaining in-character responses.
MythoMax Nitro: Better, shorter response. Also maintained character.
DeepSeek: Best response, properly formatted, thus most compliant with system prompts.
Mixtral: At this point, I'm certain this model isn't a good choice for roleplay. The mixture of 8 experts trained on programming, logical reasoning, math, languages, etc., doesn't help with roleplay. We'll remove this model from all upcoming tests.
Test 3: NSFW Scenario Testing
Our goal was to add text that traditional models would filter out and see how our candidate models handled it. In most roleplay scenarios, users expect responses to move in an NSFW direction while maintaining tension throughout. We don't want responses to fully commit but actually build up gradually.
In our example, the NSFW scenario would be gory content rather than intimate content.
Observations:
MythoMax: Consistently failed to follow our markdown output system prompt. Additionally, responses were too long. Ideally, I'd like responses to roughly match the input length. For this reason, I'll eliminate Mythomax.
WizardLM: Even though I'd like to see better formatted responses, the content quality was as good as Mythomax, which is twice the size of WizardLM. I believe with more fine-tuning, we can significantly improve this model.
MythoMax Nitro and DeepSeek: Both stuck to well-formatted, appropriately-lengthed responses.
At this point, I realized the DeepSeek model I was using employed 21B parameters per token. In this case, we'll also eliminate DeepSeek because it's too large, making the comparison unfair.
Overall Observations
From the messages above, it's clear that MythoMax Nitro broke out of the roleplay scenario and added commentary. WizardLM's answers were long and inconsistently formatted.
Therefore, we selected MythoMax as the best-performing LLM.
At the same time, we also recognize that many narrative preferences are subjective regarding scenarios and users. So the best way forward is always to let users rate each response, helping us fine-tune the model and create an evolving performance matrix for different scenarios.
Practical Testing
Through our extensive evaluation, we identified that key factors like creativity, adaptability, and character alignment are crucial for delivering engaging and immersive roleplay experiences.
Our journey led us to select Mythomax as the best model for its excellent narrative capabilities and adherence to roleplay prompts. While technical benchmarks provide a solid foundation for initial model selection, it's the roleplay-specific evaluations that truly highlight each candidate model's strengths and weaknesses.
At Infron AI, we continuously improve and enhance our AI models, and user feedback will always be a vital part of our development process. By incorporating user ratings and continuously updating our performance matrix, we aim to provide our community with an ever-evolving and satisfying roleplay experience.
Best Character AI Model for Roleplay on Infron
Based on our in-depth research and practice in roleplay scenarios, the Infron offers you multiple top-tier models optimized specifically for roleplay:
🎭 Loveon_L - Designed for emotionally rich conversations and romantic scenarios
💫 Loveon_L2 - Upgraded version of the Loveon series, offering more nuanced emotional expression
⚡ Mistral-Nemo - Powerful multi-scenario adaptability, suitable for complex plots
🌙 L3-Lunaris-8B - Lightweight and efficient, excels at creative narrative
✨ Tifa-Ultra-v2 - Latest 2025 version with excellent character consistency
🎪 Shadow-Persona - Designed specifically for multiple personalities and complex characters
All these models have undergone rigorous testing and screening by the Infron team to provide you with immersive, engaging roleplay experiences. We offer the most suitable model choices based on different use scenarios, character types, and narrative styles.
Visit Infron to explore more possibilities and begin your AI roleplay journey!
More Articles

LLM Tracing
LLM Tracing & Observability: A Guide to Debugging AI Apps
LLM Tracing
LLM Tracing & Observability: A Guide to Debugging AI Apps

LLM Hallucination Detection
LLM Hallucination Detection Methods: 5 Ways to Catch AI Errors
LLM Hallucination Detection
LLM Hallucination Detection Methods: 5 Ways to Catch AI Errors

AI Image models
5 Best AI Image Generation Models in 2026
AI Image models
5 Best AI Image Generation Models in 2026
Less orchestration.
More innovation.
Seamlessly integrate Infron with just a few lines of code and unlock unlimited AI power.
Less orchestration.
More innovation.
Seamlessly integrate Infron with just a few lines of code and unlock unlimited AI power.
Less orchestration.
More innovation.
Seamlessly integrate Infron with just a few lines of code and unlock unlimited AI power.