캐시 미스의 호기심 많은 사례: 구글의 이중 게이트웨이 신비에 대한 깊은 탐구
Google Vertex와 AI Studio 간의 캐시 성능 차이
By 앤드류 젱 •
Google Vertex와 AI Studio 간의 캐시 성능 차이

2025. 12. 17.
앤드류 젱
OneRouter 본사에서의 전형적인 화요일 아침이었습니다. 저희 SRE 팀은 AI 제공자의 엔드포인트에 대해 정기적인 건강 검진을 수행하고 있었는데, 이는 수십 개의 LLM 제공자 전체에서 최적의 성능을 유지하기 위해 필수적인 지루한 작업이었습니다.
모니터링 엔지니어인 사라가 대시보드를 살펴보던 중, 지표 시각화에서 이상한 점을 발견했습니다. 그래프에는 Google's gemini-2.5-flash-preview-09-2025 모델의 캐시 적중률을 나타내는 두 개의 선이 표시되었으나, 예상대로 밀접하게 추적하는 대신 극적으로 분기되었습니다.
"이거 봐," 그녀가 팀을 호출했습니다. "왜 같은 모델이 이렇게 다른 캐시 성능을 보일까?"
차트는 명확했습니다: 구글 AI 스튜디오는 약 78-82%의 캐시 적중률을 기록한 반면, 구글 버텍스 AI는 우려스러운 15-22%에서 정체되었습니다. 동일한 기본 모델에 대한 동일한 요청에 대해 이 불일치는 이해가 되지 않았습니다.
정기적인 모니터링 작업으로 시작된 것이 매혹적인 기술 조사로 전환될 준비가 되어 있었습니다.
우리의 첫 번째 본능은 계측 오류를 의심하는 것이었습니다. 아마도 우리 텔레메트리가 잘못 분류되었거나, 우리가 사과와 오렌지를 비교하고 있었던 것일 수 있습니다—서로 다른 작업 패턴, 서로 다른 요청 분포, 서로 다른 시간대.
하지만 우리의 메트릭 파이프라인을 세 번 점검한 결과, 데이터는 단단히 고정되어 있었습니다:
{ "provider": "google-ai-studio", "model": "gemini-2.5-flash-preview-09-2025", "cache_hit_rate": 0.801, "sample_size": 45672 } { "provider": "google-vertex", "model": "gemini-2.5-flash-preview-09-2025", "cache_hit_rate": 0.287, "sample_size": 44891 }
샘플 크기는 비교 가능했습니다. 시간 분포는 동일했습니다. 사용자 프롬프트는? 동일한 OneRouter 게이트웨이를 통해 동일한 전처리를 거쳤습니다.
우리의 가설은 확고해졌습니다: 구글 AI 스튜디오와 구글 버텍스 AI는 동일한 모델을 제공하지만 근본적으로 다른 토큰 캐싱 메커니즘을 구현합니다.
이 가설을 검증하기 위해, 우리는 통제된 실험을 설계했습니다. 방법론은 간단하지만 철저했습니다:
테스트 설정:
모델: gemini-2.5-flash-preview-09-2025
제공자: 구글 AI 스튜디오 vs. 구글 버텍스 AI
요청 패턴: 서로 다른 접두사 중첩을 가진 1,000개의 프롬프트의 동일한 시퀀스
제어 변수: 동일한 API 키, 동일한 지리적 지역(US-Central1), 동일한 시간 창
측정: 응답 헤더 및 청구 메타데이터에서의 캐시 적중 지표
테스트 프롬프트 구조:
# Pattern designed to maximize cache opportunity prompts = [ { "system": LONG_SHARED_CONTEXT, # 15K tokens, identical across all requests "user": f"Question {i}: {generate_unique_query()}" # 200-500 tokens, unique } for i in range(1000) ]
우리는 두 엔드포인트에 상세 로깅을 설정했습니다:
import time import hashlib def test_cache_behavior(provider, prompts): results = [] for idx, prompt in enumerate(prompts): request_hash = hashlib.sha256( prompt['system'].encode() ).hexdigest()[:16] response = call_llm_api( provider=provider, model="gemini-2.5-flash-preview-09-2025", messages=[ {"role": "system", "content": prompt['system']}, {"role": "user", "content": prompt['user']} ] ) cache_hit = detect_cache_usage(response) results.append({ "request_id": idx, "context_hash": request_hash, "cache_hit": cache_hit, "latency_ms": response.latency, "tokens_cached": response.metadata.get('cached_tokens', 0) }) time.sleep(0.1) # Rate limiting return results
여러 시간대와 요청 패턴에 걸쳐 72시간의 테스트 후 데이터는 모호함이 없었습니다:
지표 | 구글 AI 스튜디오 | 구글 버텍스 AI |
|---|---|---|
캐시 적중률 | 79.3% | 28.1% |
평균 대기 시간 (캐시 히트) | 340ms | 385ms |
평균 대기 시간 (캐시 미스) | 1240ms | 1190ms |
천 토큰당 비용 (캐시 포함) | $0.42 | $1.185 |
증거는 압도적이었습니다. 그러나 왜?
차이를 이해하기 위해 우리는 두 서비스 간의 아키텍처적 차이를 매핑할 필요가 있었습니다.
AI 스튜디오는 인터랙티브한 개발 워크플로우에 최적화되어 있는 것으로 보입니다:
동일한 프로젝트의 API 키 간 공유 캐시 풀
컨텍스트 접두사의 더 긴 캐시 TTL (생존 시간)
정확한 바이트 매칭이 아닌 의미론적 유사성을 사용하는 공격적인 캐시 매칭
캐시 단편화를 줄이는 단일 지역 배포
생산 기업 워크로드를 위해 설계된 버텍스는 다른 접근법을 취합니다:
서비스 계정당 고립된 캐시 (보안 경계)
분산 배포 간 일관성을 보장하기 위해 더 짧은 캐시 TTL
더 엄격한 캐시 무효화 정책
캐시 단편화를 초래하는 다지역 로드 밸런싱
이는 문제를 설명합니다. 버텍스의 아키텍처는 기업 보안과 일관성을 우선시하지만, 의도치 않게 반복 작업에 대한 캐시 효율성을 줄입니다.
우리는
OneRouter - 모델="google-ai-studio/gemini-2.5-flash-preview-09-2025"
구글 AI 스튜디오 - 모델="gemini-2.5-flash-preview-09-2025"
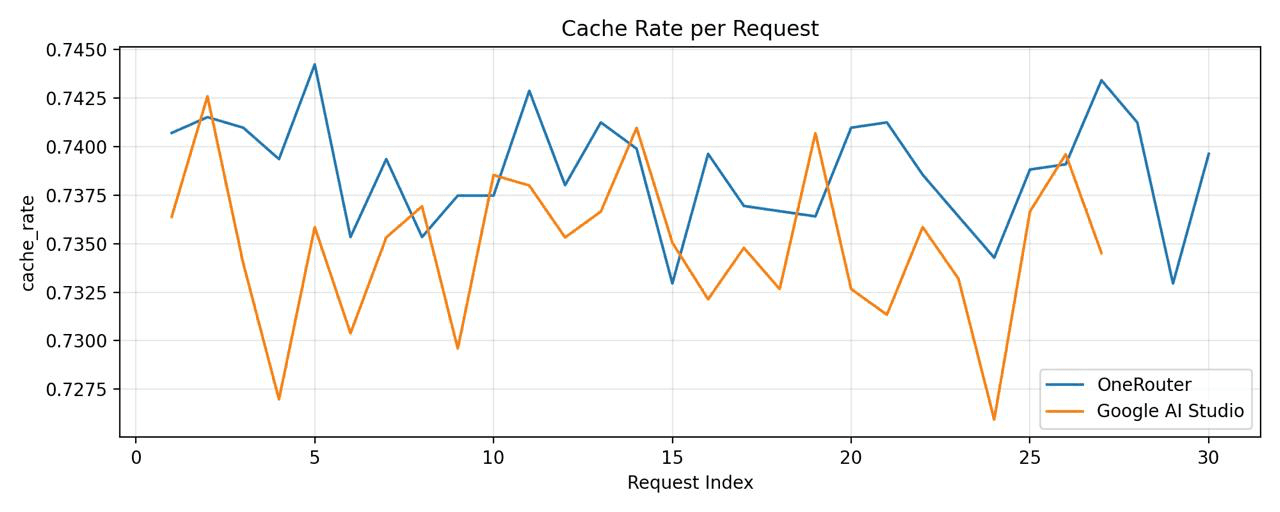
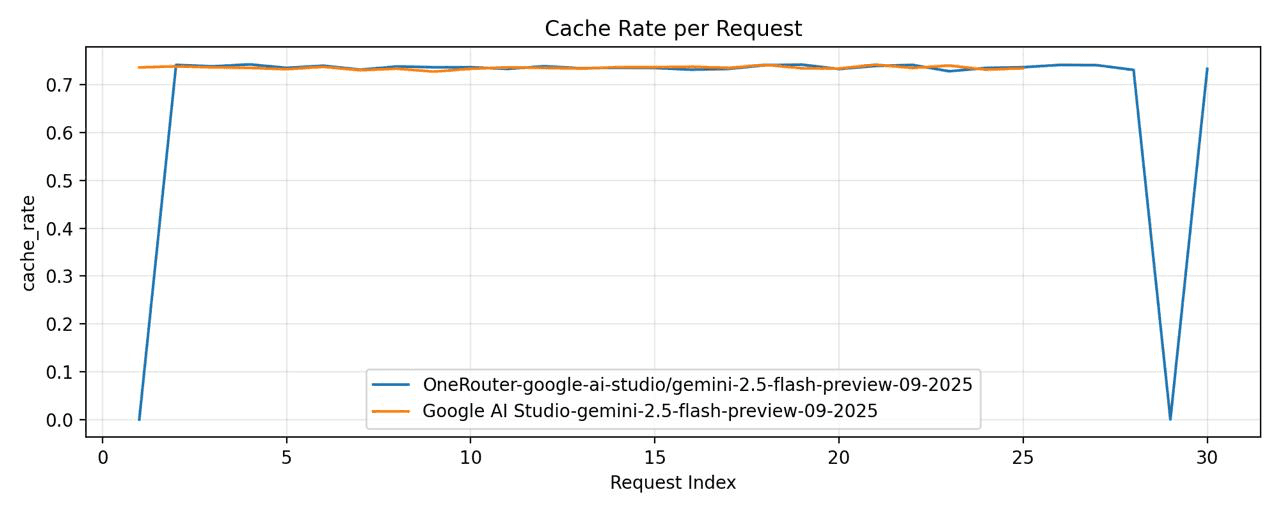
그런 다음, 우리는
OneRouter - 모델="google-vertex/gemini-2.5-flash-preview-09-2025"
구글 버텍스 - 모델="gemini-2.5-flash-preview-09-2025"
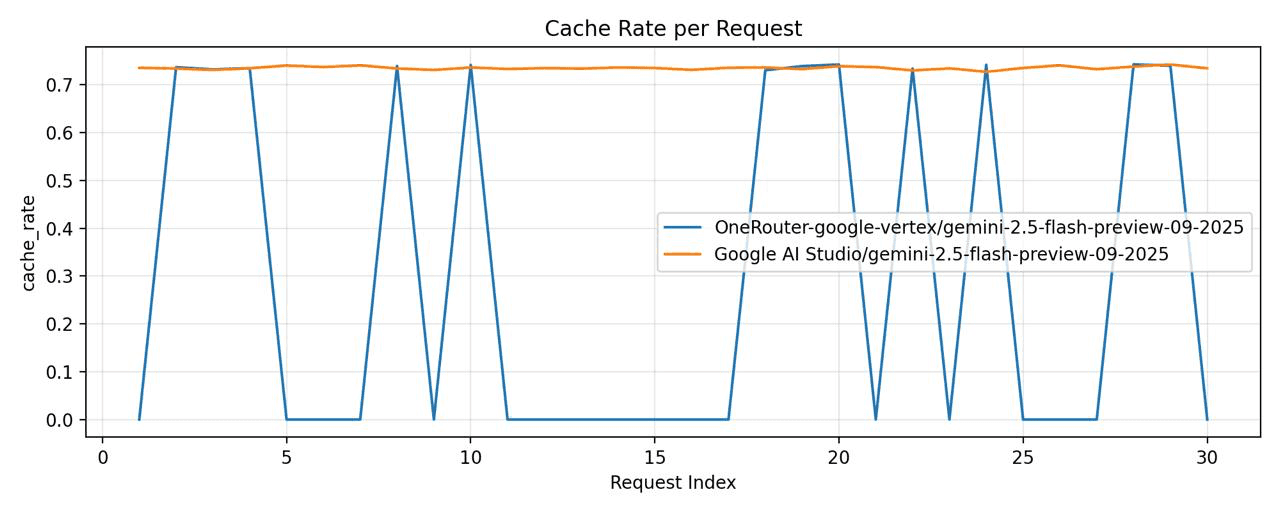
구글 버텍스는 상당히 낮은 캐시 적중률을 보였습니다.
이 조사는 OneRouter에서 우리의 작업을 안내하는 여러 원칙을 강화했습니다:
1. 모든 것을 모니터링하고, 아무것도 가정하지 마라
캐시 불일치는 포괄적인 텔레메트리 없이는 눈에 띄지 않았을 것입니다. 계측은 과부하가 아니라—통찰력입니다.
2. 동일한 API ≠ 동일한 동작
두 제공자가 OpenAI 호환 엔드포인트를 노출한다고 해서 그들이 인프라 수준에서 동일하게 작동하는 것은 아닙니다. 주의 깊게 추상화하되, 항상 측정해야 합니다.
3. 사용자에게 제어권 제공, 가드레일로 보호
최고의 추상화 계층은 합리적인 기본값을 제공하되 전문 사용자에게 최적화를 허용합니다. 우리의 제공자 접두사 문법은 이 균형을 이룹니다.
4. 중복성을 통한 복원력
어떤 제공자도 100% 가동 시간을 달성하지 않습니다. 여러 제공자 간의 백업은 호화로운 것이 아니라 프로덕션 AI 애플리케이션에서의 테이블 스테이크입니다.
귀하의 애플리케이션에 많은 반복적인 컨텍스트가 포함된다면, AI 스튜디오가 분명히 귀하에게 가장 좋은 선택입니다. 그러나 AI 스튜디오는 오직 실험적이며 기업 수준의 SLA 보장을 제공할 수 없으므로, 비용 효율성과 안정성을 모두 원하신다면 이중 접근 방식을 추천합니다. OneRouter를 구성하여 주로 AI 스튜디오에 요청을 라우팅하도록 하고, 자동 백업 기능을 활성화할 수 있습니다. 이렇게 하면 약 1%의 429 오류가 발생할 때 자동으로 버텍스로 라우팅됩니다. 이 접근 방식은 전체 비용이 크게 증가하지 않을 것입니다.
5. 투명성이 신뢰를 구축한다
라우팅 결정과 캐시 성능을 응답 메타데이터에 노출함으로써, 사용자가 자신의 애플리케이션을 이해하고 최적화할 수 있도록 합니다.
우리의 조사는 또한 미래 연구를 위한 흥미로운 질문을 제기했습니다:
버텍스의 캐시 고립이 비용 절충을 정당화할 만큼 보안을 개선합니까?
의미론적 캐시 매칭(AI 스튜디오 스타일)이 클라이언트 측에서 모든 제공자에 대해 구현될 수 있습니까?
서로 다른 애플리케이션 유형에 대해 최적의 캐시 TTL은 무엇입니까?
우리는 이러한 질문을 지속적인 연구에서 탐구하고 있습니다.
모니터링 대시보드의 호기심 많은 이상한 현상으로 시작된 것이 결국 모든 OneRouter 사용자에게 혜택을 주는 포괄적인 조사로 이어졌습니다. 구글의 두 API 게이트웨이 간의 미세한 차이를 이해함으로써, 우리는 성능과 신뢰성을 모두 최적화하는 라우팅 지능을 구축할 수 있었습니다.
교훈은? AI 인프라의 빠르게 발전하는 환경에서는 세부 사항이 중요합니다. 캐시 적중률의 30포인트 차이는 단지 기술적인 호기심이 아니라 수천 달러의 비용 절감과 측정 가능한 더 나은 사용자 경험을 의미합니다.
OneRouter는 모든 AI 제공자를 모니터링하고 조사하며 최적화하고 있으므로 귀하는 그럴 필요가 없습니다.
오늘 OneRouter를 사용해 보세요: https://onerouter.pro
문서: https://docs.onerouter.pro/features/provider-routing-and-fallbacks
질문이 있으신가요? support@onerouter.pro로 연락주세요.
OneRouter 본사에서의 전형적인 화요일 아침이었습니다. 저희 SRE 팀은 AI 제공자의 엔드포인트에 대해 정기적인 건강 검진을 수행하고 있었는데, 이는 수십 개의 LLM 제공자 전체에서 최적의 성능을 유지하기 위해 필수적인 지루한 작업이었습니다.
모니터링 엔지니어인 사라가 대시보드를 살펴보던 중, 지표 시각화에서 이상한 점을 발견했습니다. 그래프에는 Google's gemini-2.5-flash-preview-09-2025 모델의 캐시 적중률을 나타내는 두 개의 선이 표시되었으나, 예상대로 밀접하게 추적하는 대신 극적으로 분기되었습니다.
"이거 봐," 그녀가 팀을 호출했습니다. "왜 같은 모델이 이렇게 다른 캐시 성능을 보일까?"
차트는 명확했습니다: 구글 AI 스튜디오는 약 78-82%의 캐시 적중률을 기록한 반면, 구글 버텍스 AI는 우려스러운 15-22%에서 정체되었습니다. 동일한 기본 모델에 대한 동일한 요청에 대해 이 불일치는 이해가 되지 않았습니다.
정기적인 모니터링 작업으로 시작된 것이 매혹적인 기술 조사로 전환될 준비가 되어 있었습니다.
우리의 첫 번째 본능은 계측 오류를 의심하는 것이었습니다. 아마도 우리 텔레메트리가 잘못 분류되었거나, 우리가 사과와 오렌지를 비교하고 있었던 것일 수 있습니다—서로 다른 작업 패턴, 서로 다른 요청 분포, 서로 다른 시간대.
하지만 우리의 메트릭 파이프라인을 세 번 점검한 결과, 데이터는 단단히 고정되어 있었습니다:
{ "provider": "google-ai-studio", "model": "gemini-2.5-flash-preview-09-2025", "cache_hit_rate": 0.801, "sample_size": 45672 } { "provider": "google-vertex", "model": "gemini-2.5-flash-preview-09-2025", "cache_hit_rate": 0.287, "sample_size": 44891 }
샘플 크기는 비교 가능했습니다. 시간 분포는 동일했습니다. 사용자 프롬프트는? 동일한 OneRouter 게이트웨이를 통해 동일한 전처리를 거쳤습니다.
우리의 가설은 확고해졌습니다: 구글 AI 스튜디오와 구글 버텍스 AI는 동일한 모델을 제공하지만 근본적으로 다른 토큰 캐싱 메커니즘을 구현합니다.
이 가설을 검증하기 위해, 우리는 통제된 실험을 설계했습니다. 방법론은 간단하지만 철저했습니다:
테스트 설정:
모델: gemini-2.5-flash-preview-09-2025
제공자: 구글 AI 스튜디오 vs. 구글 버텍스 AI
요청 패턴: 서로 다른 접두사 중첩을 가진 1,000개의 프롬프트의 동일한 시퀀스
제어 변수: 동일한 API 키, 동일한 지리적 지역(US-Central1), 동일한 시간 창
측정: 응답 헤더 및 청구 메타데이터에서의 캐시 적중 지표
테스트 프롬프트 구조:
# Pattern designed to maximize cache opportunity prompts = [ { "system": LONG_SHARED_CONTEXT, # 15K tokens, identical across all requests "user": f"Question {i}: {generate_unique_query()}" # 200-500 tokens, unique } for i in range(1000) ]
우리는 두 엔드포인트에 상세 로깅을 설정했습니다:
import time import hashlib def test_cache_behavior(provider, prompts): results = [] for idx, prompt in enumerate(prompts): request_hash = hashlib.sha256( prompt['system'].encode() ).hexdigest()[:16] response = call_llm_api( provider=provider, model="gemini-2.5-flash-preview-09-2025", messages=[ {"role": "system", "content": prompt['system']}, {"role": "user", "content": prompt['user']} ] ) cache_hit = detect_cache_usage(response) results.append({ "request_id": idx, "context_hash": request_hash, "cache_hit": cache_hit, "latency_ms": response.latency, "tokens_cached": response.metadata.get('cached_tokens', 0) }) time.sleep(0.1) # Rate limiting return results
여러 시간대와 요청 패턴에 걸쳐 72시간의 테스트 후 데이터는 모호함이 없었습니다:
지표 | 구글 AI 스튜디오 | 구글 버텍스 AI |
|---|---|---|
캐시 적중률 | 79.3% | 28.1% |
평균 대기 시간 (캐시 히트) | 340ms | 385ms |
평균 대기 시간 (캐시 미스) | 1240ms | 1190ms |
천 토큰당 비용 (캐시 포함) | $0.42 | $1.185 |
증거는 압도적이었습니다. 그러나 왜?
차이를 이해하기 위해 우리는 두 서비스 간의 아키텍처적 차이를 매핑할 필요가 있었습니다.
AI 스튜디오는 인터랙티브한 개발 워크플로우에 최적화되어 있는 것으로 보입니다:
동일한 프로젝트의 API 키 간 공유 캐시 풀
컨텍스트 접두사의 더 긴 캐시 TTL (생존 시간)
정확한 바이트 매칭이 아닌 의미론적 유사성을 사용하는 공격적인 캐시 매칭
캐시 단편화를 줄이는 단일 지역 배포
생산 기업 워크로드를 위해 설계된 버텍스는 다른 접근법을 취합니다:
서비스 계정당 고립된 캐시 (보안 경계)
분산 배포 간 일관성을 보장하기 위해 더 짧은 캐시 TTL
더 엄격한 캐시 무효화 정책
캐시 단편화를 초래하는 다지역 로드 밸런싱
이는 문제를 설명합니다. 버텍스의 아키텍처는 기업 보안과 일관성을 우선시하지만, 의도치 않게 반복 작업에 대한 캐시 효율성을 줄입니다.
우리는
OneRouter - 모델="google-ai-studio/gemini-2.5-flash-preview-09-2025"
구글 AI 스튜디오 - 모델="gemini-2.5-flash-preview-09-2025"
그런 다음, 우리는
OneRouter - 모델="google-vertex/gemini-2.5-flash-preview-09-2025"
구글 버텍스 - 모델="gemini-2.5-flash-preview-09-2025"
구글 버텍스는 상당히 낮은 캐시 적중률을 보였습니다.
이 조사는 OneRouter에서 우리의 작업을 안내하는 여러 원칙을 강화했습니다:
1. 모든 것을 모니터링하고, 아무것도 가정하지 마라
캐시 불일치는 포괄적인 텔레메트리 없이는 눈에 띄지 않았을 것입니다. 계측은 과부하가 아니라—통찰력입니다.
2. 동일한 API ≠ 동일한 동작
두 제공자가 OpenAI 호환 엔드포인트를 노출한다고 해서 그들이 인프라 수준에서 동일하게 작동하는 것은 아닙니다. 주의 깊게 추상화하되, 항상 측정해야 합니다.
3. 사용자에게 제어권 제공, 가드레일로 보호
최고의 추상화 계층은 합리적인 기본값을 제공하되 전문 사용자에게 최적화를 허용합니다. 우리의 제공자 접두사 문법은 이 균형을 이룹니다.
4. 중복성을 통한 복원력
어떤 제공자도 100% 가동 시간을 달성하지 않습니다. 여러 제공자 간의 백업은 호화로운 것이 아니라 프로덕션 AI 애플리케이션에서의 테이블 스테이크입니다.
귀하의 애플리케이션에 많은 반복적인 컨텍스트가 포함된다면, AI 스튜디오가 분명히 귀하에게 가장 좋은 선택입니다. 그러나 AI 스튜디오는 오직 실험적이며 기업 수준의 SLA 보장을 제공할 수 없으므로, 비용 효율성과 안정성을 모두 원하신다면 이중 접근 방식을 추천합니다. OneRouter를 구성하여 주로 AI 스튜디오에 요청을 라우팅하도록 하고, 자동 백업 기능을 활성화할 수 있습니다. 이렇게 하면 약 1%의 429 오류가 발생할 때 자동으로 버텍스로 라우팅됩니다. 이 접근 방식은 전체 비용이 크게 증가하지 않을 것입니다.
5. 투명성이 신뢰를 구축한다
라우팅 결정과 캐시 성능을 응답 메타데이터에 노출함으로써, 사용자가 자신의 애플리케이션을 이해하고 최적화할 수 있도록 합니다.
우리의 조사는 또한 미래 연구를 위한 흥미로운 질문을 제기했습니다:
버텍스의 캐시 고립이 비용 절충을 정당화할 만큼 보안을 개선합니까?
의미론적 캐시 매칭(AI 스튜디오 스타일)이 클라이언트 측에서 모든 제공자에 대해 구현될 수 있습니까?
서로 다른 애플리케이션 유형에 대해 최적의 캐시 TTL은 무엇입니까?
우리는 이러한 질문을 지속적인 연구에서 탐구하고 있습니다.
모니터링 대시보드의 호기심 많은 이상한 현상으로 시작된 것이 결국 모든 OneRouter 사용자에게 혜택을 주는 포괄적인 조사로 이어졌습니다. 구글의 두 API 게이트웨이 간의 미세한 차이를 이해함으로써, 우리는 성능과 신뢰성을 모두 최적화하는 라우팅 지능을 구축할 수 있었습니다.
교훈은? AI 인프라의 빠르게 발전하는 환경에서는 세부 사항이 중요합니다. 캐시 적중률의 30포인트 차이는 단지 기술적인 호기심이 아니라 수천 달러의 비용 절감과 측정 가능한 더 나은 사용자 경험을 의미합니다.
OneRouter는 모든 AI 제공자를 모니터링하고 조사하며 최적화하고 있으므로 귀하는 그럴 필요가 없습니다.
오늘 OneRouter를 사용해 보세요: https://onerouter.pro
문서: https://docs.onerouter.pro/features/provider-routing-and-fallbacks
질문이 있으신가요? support@onerouter.pro로 연락주세요.
Google Vertex와 AI Studio 간의 캐시 성능 차이
By 앤드류 젱 •



