클로드 코드로 긴 작업에서 Kimi-K2-Thinking이 어떻게 안정적으로 유지되는가
원라우터는 클로드 코드를 지원합니다.
By 앤드류 젱 •
원라우터는 클로드 코드를 지원합니다.

2025. 12. 15.
앤드류 젱
오늘날 개발자와 연구자들은 대규모 언어 모델을 선택할 때 세 가지 주요 과제에 직면해 있습니다: 장기적 추론 유지, 맥락 한계 관리, 운영 비용 제어. Claude Sonnet 4와 GPT-5와 같은 전통적인 폐쇄형 모델은 강력한 성능을 제공하지만 다단계 또는 도구 기반 워크플로를 처리할 때 비용이 증가하고 제약을 받습니다.
이 기사는 Kimi-K2-Thinking—단계별 추론, 동적 도구 통합 및 대규모 맥락 용량을 결합한 개방형 에이전트 지향 대안—을 소개합니다. 비교, 벤치마크 및 설정 가이드를 통해 Kimi-K2가 긴 복잡한 AI 작업에서 일관성, 규모 및 비용 효율성의 문제를 해결하는 방법을 설명합니다.
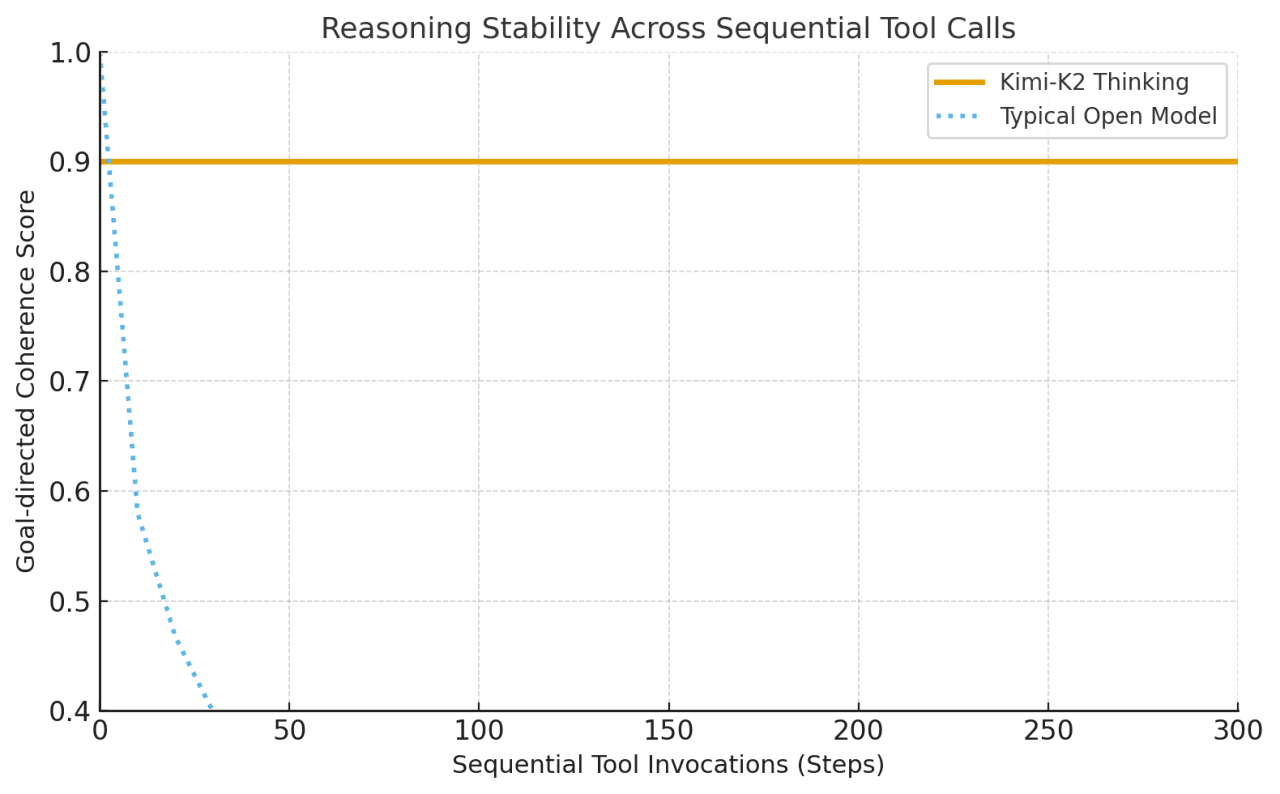
Kimi-K2 Thinking은 단계별 사고 체인 추론과 동적 기능/도구 호출을 교차하여 사용하는 "사고 에이전트"로 구축되었습니다. 일반적인 모델과 달리 몇 번의 도구 사용 후에도 흐트러지거나 일관성을 잃는 경우가 있는 Kimi-K2는 인간 개입 없이 200–300개의 연속적 도구 호출에 걸쳐 안정적인 목표 지향 행동을 유지합니다.
이는 주요 도약입니다: 이전 개방형 모델은 30–50단계 후에 악화되는 경향이 있었습니다. 즉, Kimi-K2는 복잡한 문제를 해결하기 위해 길게 나아가면서 수백 개의 실행 단계를 한 세션에서 처리할 수 있습니다.
Anthropic의 Claude는 도구와 함께하는 그러한 "교차 사고"로 알려져 있었지만 Kimi-K2는 이 기능을 오픈 소스 영역으로 가져옵니다.
이 아키텍처는 규모, 효율성 및 안정성을 균형 있게 조정하여 Kimi-K2-Thinking이 긴 시퀀스에 걸쳐 복잡하고 도구가 풍부한 추론을 지속할 수 있게 합니다.
아키텍처 특징 | 실용적 장점 |
|---|---|
전문가 혼합(MoE) | 비용을 증가시키지 않고 모델 용량을 확장하며 각 작업에 가장 관련성이 높은 전문가를 선택합니다. |
1T 매개변수 / 32B 활성화 | 대규모 지식과 효율적인 계산을 결합합니다. |
61개 층과 1개 밀집 층 | 단계 간 깊게 일관된 추론을 유지합니다. |
384명의 전문가, 토큰당 8명 활성화 | 다양한 문제에 대한 전문화 및 적응성을 향상시킵니다. |
256K 맥락 길이 | 매우 긴 입력을 처리하고 긴 추론 체인에서 연속성을 유지합니다. |
MLA(다중 헤드 잠재 주의) | 장거리 집중을 강화하고 메모리 부담을 줄입니다. |
SwiGLU 활성화 | 훈련을 안정시키고 부드럽고 정확한 추론을 지원합니다. |
Kimi-K2는 주요 수학 벤치마크에서 GPT-5 및 Claude와 유사한 성능을 보이지만 MMLU-Pro/Redux, 긴 형식 작성 및 코드에서는 GPT-5 및 Claude에 비해 약간 뒤쳐져 있습니다.
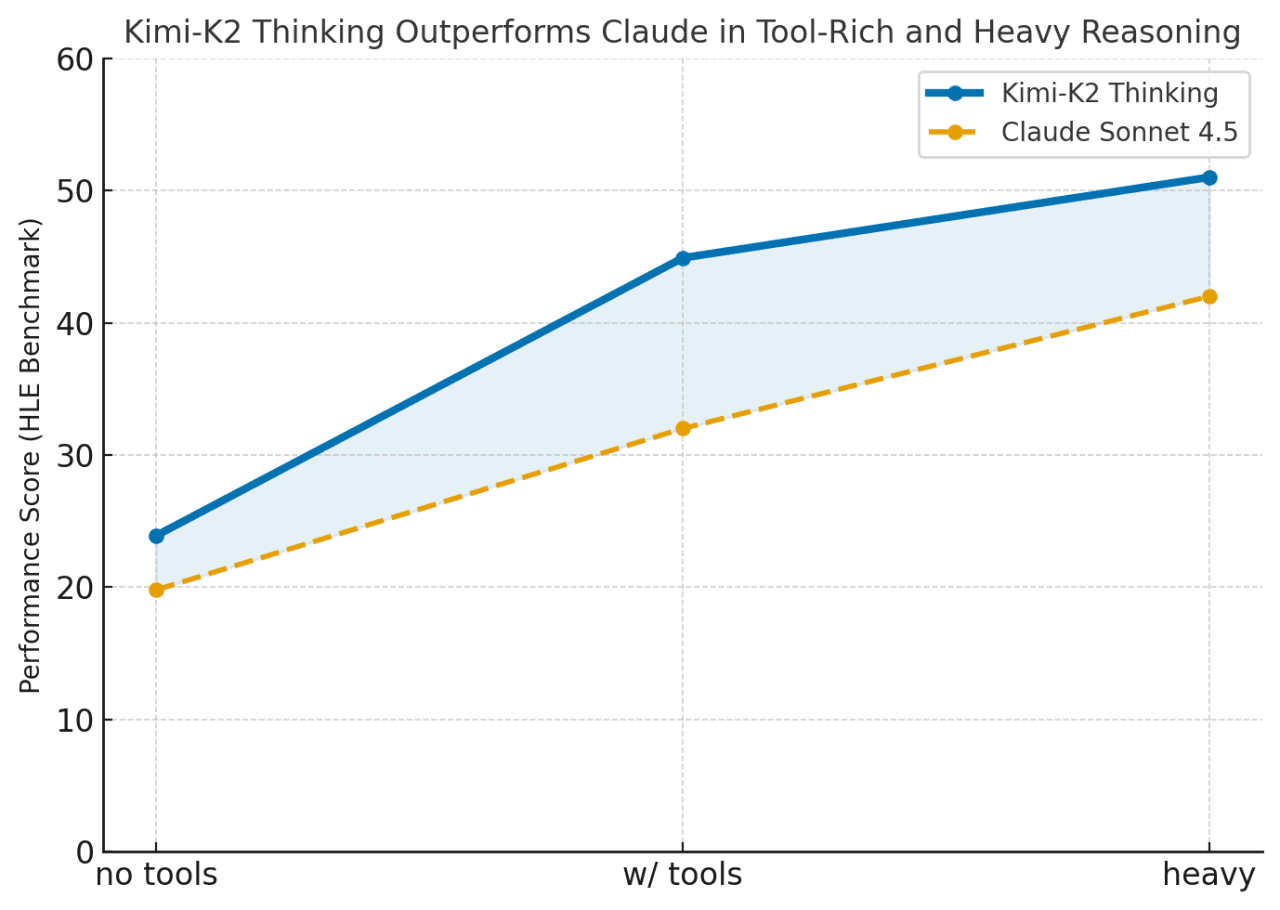
Kimi-K2는 도구가 활성화되거나 작업이 긴 체계적 추론을 요구할 때 성능이 우수합니다(HLE와 도구 = 44.9 대 Claude 32.0). Kimi-K2는 Claude와 같은 폐쇄형 모델과 오픈 소스 시스템 간의 격차를 해소하며 지속적이고 도구가 풍부한 문제 해결에 뛰어납니다.
–
카테고리 | 벤치마크 | 설정 | Kimi K2 Thinking | GPT-5 (높음) | Claude Sonnet 4.5 (사고) | Kimi K2 0905 | DeepSeek-V3.2 | Grok-4 |
|---|---|---|---|---|---|---|---|---|
추론 / 수학 | HLE | 도구 없음 | 23.9 | 26.3 | 19.8 | 7.9 | 19.8 | 25.4 |
HLE | 도구 사용 | 44.9 | 41.7 | 32.0 | 21.7 | 20.3 | 41.0 | |
HLE | 무거움 | 51.0 | 42.0 | – | – | – | 50.7 | |
AIME25 | 도구 없음 | 94.5 | 94.6 | 87.0 | 51.0 | 89.3 | 91.7 | |
AIME25 | 파이썬 사용 | 99.1 | 99.6 | 100.0 | 75.2 | 58.1 | 98.8 | |
AIME25 | 무거움 | 100.0 | 100.0 | – | – | – | 100.0 | |
HMMT25 | 도구 없음 | 89.4 | 93.3 | 74.6 | 38.8 | 83.6 | 90.0 | |
HMMT25 | 파이썬 사용 | 95.1 | 96.7 | 88.8 | 70.4 | 49.5 | 93.9 | |
HMMT25 | 무거움 | 97.5 | 100.0 | – | – | – | 96.7 | |
IMO-AnswerBench | 도구 없음 | 78.6 | 76.0 | 65.9 | 45.8 | 76.0 | 73.1 | |
GPQA | 도구 없음 | 84.5 | 85.7 | 83.4 | 74.2 | 79.9 | 87.5 | |
일반 작업 | MMLU-Pro | 도구 없음 | 84.6 | 87.1 | 87.5 | 81.9 | 85.0 | – |
MMLU-Redux | 도구 없음 | 94.4 | 95.3 | 95.6 | 92.7 | 93.7 | – | |
긴 형식 작성 | 도구 없음 | 73.8 | 71.4 | 79.8 | 62.8 | 72.5 | – | |
HealthBench | 도구 없음 | 58.0 | 67.2 | 44.2 | 43.8 | 46.9 | – | |
에이전틱 검색 | BrowseComp | 도구 사용 | 60.2 | 54.9 | 24.1 | 7.4 | 40.1 | – |
BrowseComp-ZH | 도구 사용 | 62.3 | 63.0 | 42.4 | 22.2 | 47.9 | – | |
Seal-0 | 도구 사용 | 56.3 | 51.4 | 53.4 | 25.2 | 38.5 |
FinSearchComp-T3
도구 사용
47.4
48.5
44.0
10.4
27.0
–
Frames
도구 사용
87.0
86.0
85.0
58.1
80.2
–
코딩 작업
SWE-bench Verified
도구 사용
71.3
74.9
77.2
69.2
67.8
–
SWE-bench Multilingual
도구 사용
61.1
55.3
68.0
55.9
57.9
–
Multi-SWE-bench
도구 사용
41.9
39.3
44.3
33.5
30.6
–
SciCode
도구 없음
44.8
42.9
44.7
30.7
37.7
–
LiveCodeBench V6
도구 없음
83.1
87.0
64.0
56.1
74.1
–
OJ-Bench (cpp)
도구 없음
48.7
56.2
30.4
25.5
38.2
–
Terminal-Bench
시뮬레이션된 도구 사용 (JSON)
47.1
43.8
51.0
44.5
–
–
도구 없음: 순수 언어 추론, 외부 도구 없음.
도구 사용: 외부 도구를 호출할 수 있음 (예: 검색, 코드).
파이썬 사용: 계산에 파이썬만 사용.
시뮬레이션된 도구 사용 (JSON): JSON 형식으로 도구 호출을 시뮬레이션.
무거움: 고강도, 긴 체인 추론 테스트.
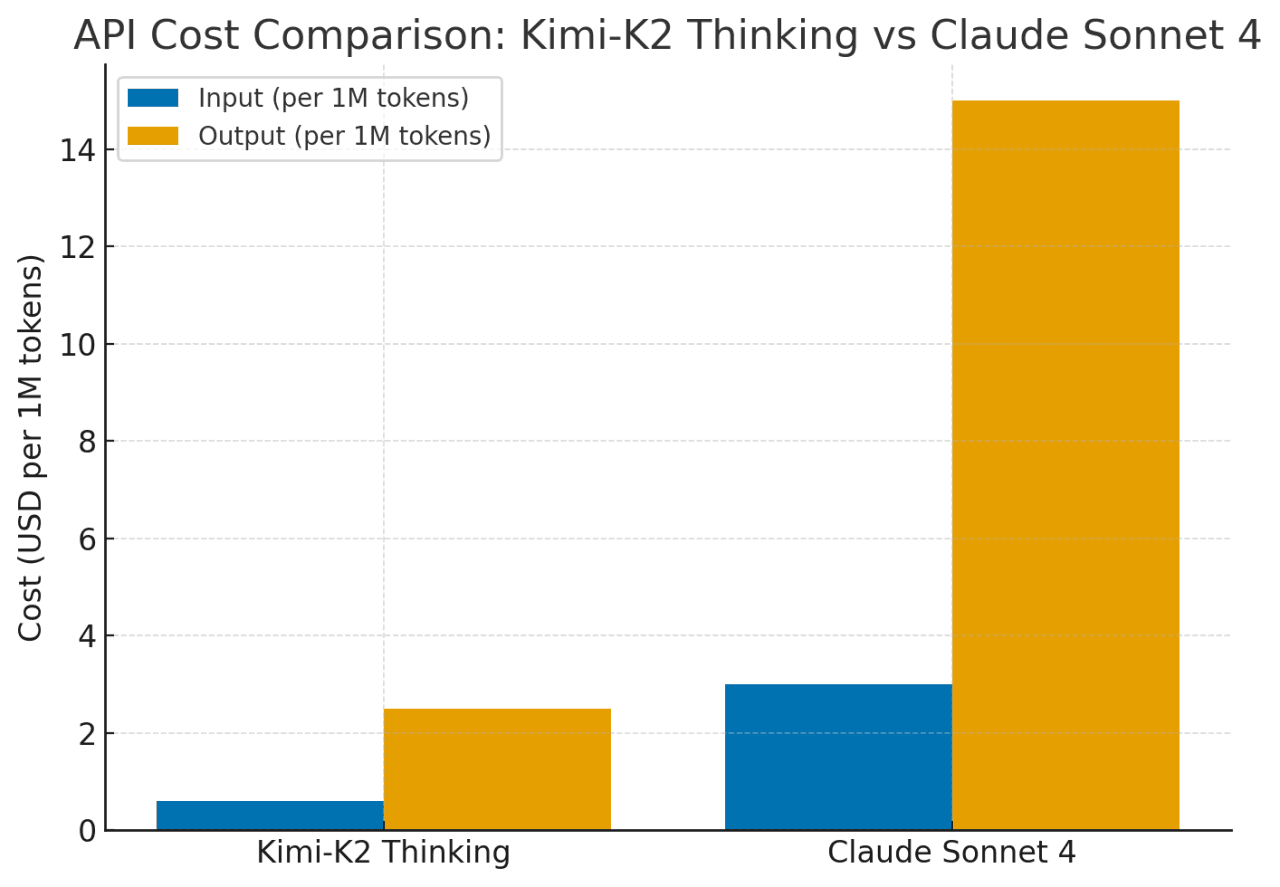
Kimi-K2는 Claude Sonnet 4와 유사한 기능을 약 75–80% 더 낮은 비용으로 제공합니다. 그 가격은 긴 맥락에 대해 평평하게 유지되며(최대 256K 토큰) 혹은 빈번한 도구 사용에도 간섭 받지 않으며, Claude의 비용은 확장된 맥락과 에이전트 작업에 대해 급격히 상승합니다. 요약하자면, Kimi-K2는 복잡하고 긴 추론 작업에 대해 훨씬 더 나은 비용 효율성으로 Claude/GPT 수준의 성능을 제공합니다.
OneRouter는 현재 가장 저렴한 전체 맥락 Kimi-K2-Thinking API를 제공합니다.
OneRouter는 262K 맥락과 $0.6/입력 및 $2.5/출력 비용을 제공하며, 구조화된 출력 및 함수 호출을 지원하여 Kimi K2 Thinking의 코드 에이전트 잠재력을 극대화하는 데 강력한 지원을 제공합니다.

지금 OneRouter는 Anthropic SDK 호환 LLM API 서비스를 제공하여, Claude 코드에서 OneRouter LLM 모델을 쉽게 사용하여 작업을 완료할 수 있도록 합니다. 아래의 가이드를 참조하여 통합 프로세스를 완료하세요.
OneRouter를 사용하기 시작하는 첫 번째 단계는 계정을 만드는 것과 API 키를 얻는 것입니다.
Claude 코드를 설치하기 전에 로컬 환경에 Node.js 18 이상가 설치되어 있는지 확인하세요.
Claude 코드를 설치하려면 다음 명령을 실행하세요:
npm install -g @anthropic-ai/claude-code
터미널을 열고 환경 변수를 다음과 같이 설정하세요:
# Set the Anthropic SDK compatible API endpoint provided by OneRouter. export ANTHROPIC_BASE_URL="https://llm.onerouter.pro" export ANTHROPIC_AUTH_TOKEN="<OneRouter API Key>" # Set the model provided by OneRouter. export ANTHROPIC_MODEL="kimi-k2-thinking" export ANTHROPIC_SMALL_FAST_MODEL="kimi-k2-thinking" export ANTHROPIC_DEFAULT_HAIKU_MODEL="kimi-k2-thinking" export ANTHROPIC_DEFAULT_OPUS_MODEL="kimi-k2-thinking" export ANTHROPIC_DEFAULT_SONNET_MODEL="kimi-k2-thinking"
다음으로, 프로젝트 디렉터리로 이동하여 Claude 코드를 시작합니다. 새 상호작용 세션에서 Claude 코드 프롬프트를 볼 수 있습니다:
cd <your-project-directory> claude
OneRouter 일반 변환 레이어를 사용하면 에이전트 논리를 변경하지 않고도 OneRouter의 모든 모델에서 Claude Agent SDK를 실행할 수 있습니다.
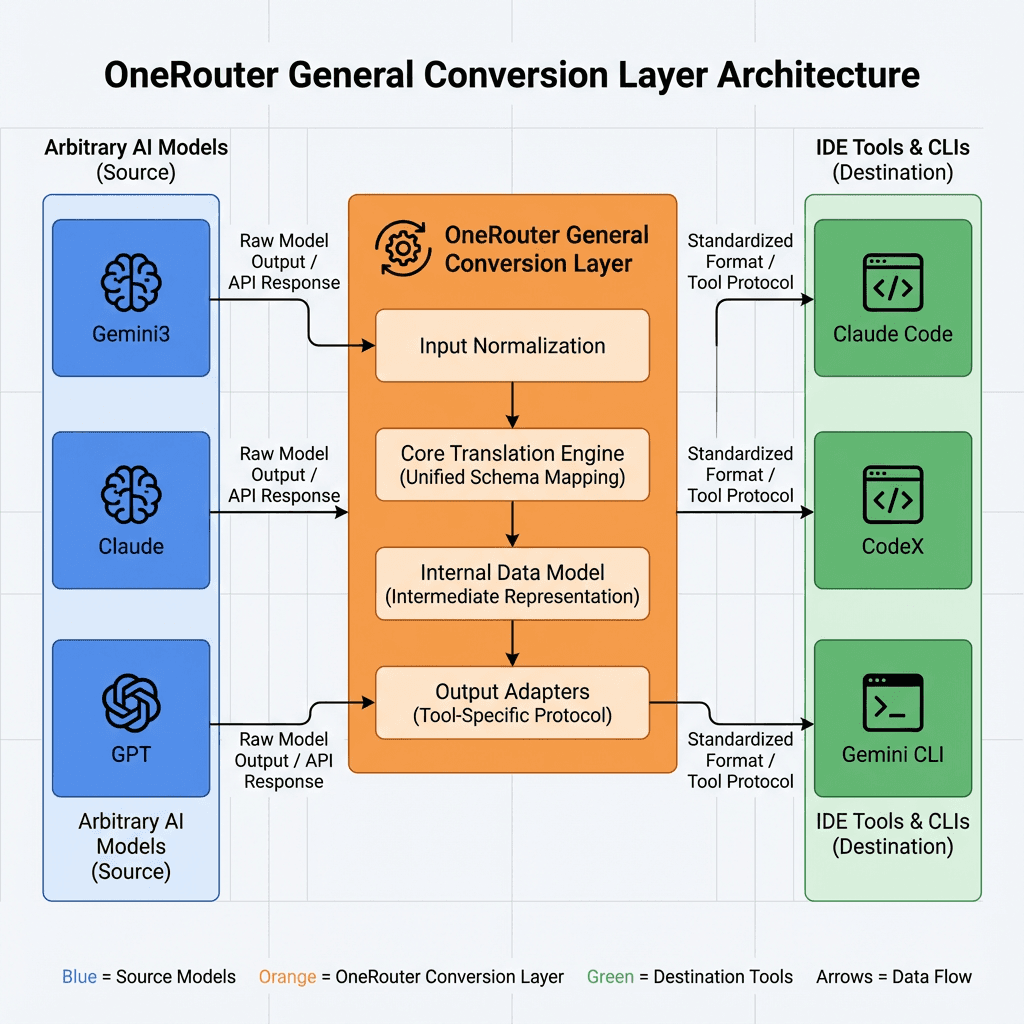
OneRouter 일반 변환 레이어를 사용하면 개발자는 동일한 SDK API를 계속 사용할 수 있습니다. 변환 레이어는 제공한 모델 문자열에 맞는 Anthropic 스타일 메시지 요청을 상위 모델(Anthropic, OpenAI 또는 OneRouter의 기타 모델)으로 변환합니다.
Kimi-K2 Thinking을 사용할 때 — 작업 특성 및 일치 강점
작업 특성: 다단계 워크플로, 자율적 도구 호출, 지속적인 추론(예: 연구 보조원, 데이터 마이닝 에이전트 또는 자동 코더).
Kimi-K2는 해결합니다: 수백 단계에 걸쳐 일관성 있는 추론을 유지합니다; GPT-5 또는 Claude가 긴 시퀀스에서 집중력을 잃는 동안 계획, 검색 및 코딩을 통합합니다.
작업 특성: 긴 문서, 전체 코드베이스 또는 여러 파일을 한 번에 제공해야 합니다.
Kimi-K2는 해결합니다: 기본적으로 256 K 토큰 컨텍스트를 정액으로 제공하며, 대량 입력을 청크화 없이 처리할 수 있습니다. 이는 Claude 또는 GPT-4에서 보이는 높은 긴 컨텍스트 요금이 없습니다.
작업 특성: 대규모 실행 또는 엄격한 예산(매일 수백만 개의 토큰).
Kimi-K2는 해결합니다: 대략 4–6× 저렴한 비용으로 Claude/GPT 수준의 추론을 제공하여 스타트업 및 지속적인 작업에 대한 진보된 추론을 경제적으로 추진합니다.
작업 특성: 복잡한 추론, 구조화된 QA, 또는 폐쇄형 모델이 주로 등장하던 수학적 논리.
Kimi-K2는 해결합니다: AIME, HMMT, 그리고 GPQA Diamond에서 GPT-5 및 Claude 4.5와 동등하거나 초과하는 성능을 발휘하여, 이제 오픈 모델도 추론 중심의 도메인에서 최전선 수준으로 이룰 수 있다는 사실을 입증합니다.
Kimi-K2-Thinking은 폐쇄형 독점 시스템과 오픈 혁신 간의 격차를 연결합니다. 그것은 75–80% 낮은 비용으로 거의 Claude의 성능을 제공하며, 256K 컨텍스트 창을 지원하고 수백 개의 추론 또는 도구 사용 단계를 이동하여 흐트러짐 없이 지속됩니다. 심층 추론, 에이전틱 워크플로 또는 오픈 소스 배포가 필요한 개발자에게 Kimi-K2는 진보된 AI 추론에서 비용 효율성을 재정의하는 실용적이고 확장 가능한 솔루션을 제공합니다.
Kimi-K2는 200–300 도구 호출을 통해 일관된 추론을 유지하며, Claude Sonnet 4의 가격이 긴 맥락과 도구 작용 시 급격히 상승하는 것에 비해 최대 5배 저렴합니다.
예. 코드 작성을 효과적으로 할 수 있지만, 간단한 일회성 코딩보다는 추론 중심적이거나 다단계 도구 기반 프로젝트에서 더 잘 작동합니다.
기본적으로 256K 토큰을 지원하여 전체 코드베이스나 문서를 한 번에 처리할 수 있습니다. Claude 또는 GPT 모델의 긴 컨텍스트에서 발견되는 추가 비용 없이 처리합니다.
OneRouter는 단일 엔드포인트를 통해 수백 개의 AI 모델에 대한 액세스를 제공하는 통합 API를 제공하며, 자동으로 예비 처리를 수행하고 가장 비용 효율적인 옵션을 선택합니다. 선호하는 SDK나 프레임워크를 사용하여 몇 줄의 코드로 시작해 보세요.
오늘날 개발자와 연구자들은 대규모 언어 모델을 선택할 때 세 가지 주요 과제에 직면해 있습니다: 장기적 추론 유지, 맥락 한계 관리, 운영 비용 제어. Claude Sonnet 4와 GPT-5와 같은 전통적인 폐쇄형 모델은 강력한 성능을 제공하지만 다단계 또는 도구 기반 워크플로를 처리할 때 비용이 증가하고 제약을 받습니다.
이 기사는 Kimi-K2-Thinking—단계별 추론, 동적 도구 통합 및 대규모 맥락 용량을 결합한 개방형 에이전트 지향 대안—을 소개합니다. 비교, 벤치마크 및 설정 가이드를 통해 Kimi-K2가 긴 복잡한 AI 작업에서 일관성, 규모 및 비용 효율성의 문제를 해결하는 방법을 설명합니다.
Kimi-K2 Thinking은 단계별 사고 체인 추론과 동적 기능/도구 호출을 교차하여 사용하는 "사고 에이전트"로 구축되었습니다. 일반적인 모델과 달리 몇 번의 도구 사용 후에도 흐트러지거나 일관성을 잃는 경우가 있는 Kimi-K2는 인간 개입 없이 200–300개의 연속적 도구 호출에 걸쳐 안정적인 목표 지향 행동을 유지합니다.
이는 주요 도약입니다: 이전 개방형 모델은 30–50단계 후에 악화되는 경향이 있었습니다. 즉, Kimi-K2는 복잡한 문제를 해결하기 위해 길게 나아가면서 수백 개의 실행 단계를 한 세션에서 처리할 수 있습니다.
Anthropic의 Claude는 도구와 함께하는 그러한 "교차 사고"로 알려져 있었지만 Kimi-K2는 이 기능을 오픈 소스 영역으로 가져옵니다.
이 아키텍처는 규모, 효율성 및 안정성을 균형 있게 조정하여 Kimi-K2-Thinking이 긴 시퀀스에 걸쳐 복잡하고 도구가 풍부한 추론을 지속할 수 있게 합니다.
아키텍처 특징 | 실용적 장점 |
|---|---|
전문가 혼합(MoE) | 비용을 증가시키지 않고 모델 용량을 확장하며 각 작업에 가장 관련성이 높은 전문가를 선택합니다. |
1T 매개변수 / 32B 활성화 | 대규모 지식과 효율적인 계산을 결합합니다. |
61개 층과 1개 밀집 층 | 단계 간 깊게 일관된 추론을 유지합니다. |
384명의 전문가, 토큰당 8명 활성화 | 다양한 문제에 대한 전문화 및 적응성을 향상시킵니다. |
256K 맥락 길이 | 매우 긴 입력을 처리하고 긴 추론 체인에서 연속성을 유지합니다. |
MLA(다중 헤드 잠재 주의) | 장거리 집중을 강화하고 메모리 부담을 줄입니다. |
SwiGLU 활성화 | 훈련을 안정시키고 부드럽고 정확한 추론을 지원합니다. |
Kimi-K2는 주요 수학 벤치마크에서 GPT-5 및 Claude와 유사한 성능을 보이지만 MMLU-Pro/Redux, 긴 형식 작성 및 코드에서는 GPT-5 및 Claude에 비해 약간 뒤쳐져 있습니다.
Kimi-K2는 도구가 활성화되거나 작업이 긴 체계적 추론을 요구할 때 성능이 우수합니다(HLE와 도구 = 44.9 대 Claude 32.0). Kimi-K2는 Claude와 같은 폐쇄형 모델과 오픈 소스 시스템 간의 격차를 해소하며 지속적이고 도구가 풍부한 문제 해결에 뛰어납니다.
–
카테고리 | 벤치마크 | 설정 | Kimi K2 Thinking | GPT-5 (높음) | Claude Sonnet 4.5 (사고) | Kimi K2 0905 | DeepSeek-V3.2 | Grok-4 |
|---|---|---|---|---|---|---|---|---|
추론 / 수학 | HLE | 도구 없음 | 23.9 | 26.3 | 19.8 | 7.9 | 19.8 | 25.4 |
HLE | 도구 사용 | 44.9 | 41.7 | 32.0 | 21.7 | 20.3 | 41.0 | |
HLE | 무거움 | 51.0 | 42.0 | – | – | – | 50.7 | |
AIME25 | 도구 없음 | 94.5 | 94.6 | 87.0 | 51.0 | 89.3 | 91.7 | |
AIME25 | 파이썬 사용 | 99.1 | 99.6 | 100.0 | 75.2 | 58.1 | 98.8 | |
AIME25 | 무거움 | 100.0 | 100.0 | – | – | – | 100.0 | |
HMMT25 | 도구 없음 | 89.4 | 93.3 | 74.6 | 38.8 | 83.6 | 90.0 | |
HMMT25 | 파이썬 사용 | 95.1 | 96.7 | 88.8 | 70.4 | 49.5 | 93.9 | |
HMMT25 | 무거움 | 97.5 | 100.0 | – | – | – | 96.7 | |
IMO-AnswerBench | 도구 없음 | 78.6 | 76.0 | 65.9 | 45.8 | 76.0 | 73.1 | |
GPQA | 도구 없음 | 84.5 | 85.7 | 83.4 | 74.2 | 79.9 | 87.5 | |
일반 작업 | MMLU-Pro | 도구 없음 | 84.6 | 87.1 | 87.5 | 81.9 | 85.0 | – |
MMLU-Redux | 도구 없음 | 94.4 | 95.3 | 95.6 | 92.7 | 93.7 | – | |
긴 형식 작성 | 도구 없음 | 73.8 | 71.4 | 79.8 | 62.8 | 72.5 | – | |
HealthBench | 도구 없음 | 58.0 | 67.2 | 44.2 | 43.8 | 46.9 | – | |
에이전틱 검색 | BrowseComp | 도구 사용 | 60.2 | 54.9 | 24.1 | 7.4 | 40.1 | – |
BrowseComp-ZH | 도구 사용 | 62.3 | 63.0 | 42.4 | 22.2 | 47.9 | – | |
Seal-0 | 도구 사용 | 56.3 | 51.4 | 53.4 | 25.2 | 38.5 |
FinSearchComp-T3
도구 사용
47.4
48.5
44.0
10.4
27.0
–
Frames
도구 사용
87.0
86.0
85.0
58.1
80.2
–
코딩 작업
SWE-bench Verified
도구 사용
71.3
74.9
77.2
69.2
67.8
–
SWE-bench Multilingual
도구 사용
61.1
55.3
68.0
55.9
57.9
–
Multi-SWE-bench
도구 사용
41.9
39.3
44.3
33.5
30.6
–
SciCode
도구 없음
44.8
42.9
44.7
30.7
37.7
–
LiveCodeBench V6
도구 없음
83.1
87.0
64.0
56.1
74.1
–
OJ-Bench (cpp)
도구 없음
48.7
56.2
30.4
25.5
38.2
–
Terminal-Bench
시뮬레이션된 도구 사용 (JSON)
47.1
43.8
51.0
44.5
–
–
도구 없음: 순수 언어 추론, 외부 도구 없음.
도구 사용: 외부 도구를 호출할 수 있음 (예: 검색, 코드).
파이썬 사용: 계산에 파이썬만 사용.
시뮬레이션된 도구 사용 (JSON): JSON 형식으로 도구 호출을 시뮬레이션.
무거움: 고강도, 긴 체인 추론 테스트.
Kimi-K2는 Claude Sonnet 4와 유사한 기능을 약 75–80% 더 낮은 비용으로 제공합니다. 그 가격은 긴 맥락에 대해 평평하게 유지되며(최대 256K 토큰) 혹은 빈번한 도구 사용에도 간섭 받지 않으며, Claude의 비용은 확장된 맥락과 에이전트 작업에 대해 급격히 상승합니다. 요약하자면, Kimi-K2는 복잡하고 긴 추론 작업에 대해 훨씬 더 나은 비용 효율성으로 Claude/GPT 수준의 성능을 제공합니다.
OneRouter는 현재 가장 저렴한 전체 맥락 Kimi-K2-Thinking API를 제공합니다.
OneRouter는 262K 맥락과 $0.6/입력 및 $2.5/출력 비용을 제공하며, 구조화된 출력 및 함수 호출을 지원하여 Kimi K2 Thinking의 코드 에이전트 잠재력을 극대화하는 데 강력한 지원을 제공합니다.
지금 OneRouter는 Anthropic SDK 호환 LLM API 서비스를 제공하여, Claude 코드에서 OneRouter LLM 모델을 쉽게 사용하여 작업을 완료할 수 있도록 합니다. 아래의 가이드를 참조하여 통합 프로세스를 완료하세요.
OneRouter를 사용하기 시작하는 첫 번째 단계는 계정을 만드는 것과 API 키를 얻는 것입니다.
Claude 코드를 설치하기 전에 로컬 환경에 Node.js 18 이상가 설치되어 있는지 확인하세요.
Claude 코드를 설치하려면 다음 명령을 실행하세요:
npm install -g @anthropic-ai/claude-code
터미널을 열고 환경 변수를 다음과 같이 설정하세요:
# Set the Anthropic SDK compatible API endpoint provided by OneRouter. export ANTHROPIC_BASE_URL="https://llm.onerouter.pro" export ANTHROPIC_AUTH_TOKEN="<OneRouter API Key>" # Set the model provided by OneRouter. export ANTHROPIC_MODEL="kimi-k2-thinking" export ANTHROPIC_SMALL_FAST_MODEL="kimi-k2-thinking" export ANTHROPIC_DEFAULT_HAIKU_MODEL="kimi-k2-thinking" export ANTHROPIC_DEFAULT_OPUS_MODEL="kimi-k2-thinking" export ANTHROPIC_DEFAULT_SONNET_MODEL="kimi-k2-thinking"
다음으로, 프로젝트 디렉터리로 이동하여 Claude 코드를 시작합니다. 새 상호작용 세션에서 Claude 코드 프롬프트를 볼 수 있습니다:
cd <your-project-directory> claude
OneRouter 일반 변환 레이어를 사용하면 에이전트 논리를 변경하지 않고도 OneRouter의 모든 모델에서 Claude Agent SDK를 실행할 수 있습니다.
OneRouter 일반 변환 레이어를 사용하면 개발자는 동일한 SDK API를 계속 사용할 수 있습니다. 변환 레이어는 제공한 모델 문자열에 맞는 Anthropic 스타일 메시지 요청을 상위 모델(Anthropic, OpenAI 또는 OneRouter의 기타 모델)으로 변환합니다.
Kimi-K2 Thinking을 사용할 때 — 작업 특성 및 일치 강점
작업 특성: 다단계 워크플로, 자율적 도구 호출, 지속적인 추론(예: 연구 보조원, 데이터 마이닝 에이전트 또는 자동 코더).
Kimi-K2는 해결합니다: 수백 단계에 걸쳐 일관성 있는 추론을 유지합니다; GPT-5 또는 Claude가 긴 시퀀스에서 집중력을 잃는 동안 계획, 검색 및 코딩을 통합합니다.
작업 특성: 긴 문서, 전체 코드베이스 또는 여러 파일을 한 번에 제공해야 합니다.
Kimi-K2는 해결합니다: 기본적으로 256 K 토큰 컨텍스트를 정액으로 제공하며, 대량 입력을 청크화 없이 처리할 수 있습니다. 이는 Claude 또는 GPT-4에서 보이는 높은 긴 컨텍스트 요금이 없습니다.
작업 특성: 대규모 실행 또는 엄격한 예산(매일 수백만 개의 토큰).
Kimi-K2는 해결합니다: 대략 4–6× 저렴한 비용으로 Claude/GPT 수준의 추론을 제공하여 스타트업 및 지속적인 작업에 대한 진보된 추론을 경제적으로 추진합니다.
작업 특성: 복잡한 추론, 구조화된 QA, 또는 폐쇄형 모델이 주로 등장하던 수학적 논리.
Kimi-K2는 해결합니다: AIME, HMMT, 그리고 GPQA Diamond에서 GPT-5 및 Claude 4.5와 동등하거나 초과하는 성능을 발휘하여, 이제 오픈 모델도 추론 중심의 도메인에서 최전선 수준으로 이룰 수 있다는 사실을 입증합니다.
Kimi-K2-Thinking은 폐쇄형 독점 시스템과 오픈 혁신 간의 격차를 연결합니다. 그것은 75–80% 낮은 비용으로 거의 Claude의 성능을 제공하며, 256K 컨텍스트 창을 지원하고 수백 개의 추론 또는 도구 사용 단계를 이동하여 흐트러짐 없이 지속됩니다. 심층 추론, 에이전틱 워크플로 또는 오픈 소스 배포가 필요한 개발자에게 Kimi-K2는 진보된 AI 추론에서 비용 효율성을 재정의하는 실용적이고 확장 가능한 솔루션을 제공합니다.
Kimi-K2는 200–300 도구 호출을 통해 일관된 추론을 유지하며, Claude Sonnet 4의 가격이 긴 맥락과 도구 작용 시 급격히 상승하는 것에 비해 최대 5배 저렴합니다.
예. 코드 작성을 효과적으로 할 수 있지만, 간단한 일회성 코딩보다는 추론 중심적이거나 다단계 도구 기반 프로젝트에서 더 잘 작동합니다.
기본적으로 256K 토큰을 지원하여 전체 코드베이스나 문서를 한 번에 처리할 수 있습니다. Claude 또는 GPT 모델의 긴 컨텍스트에서 발견되는 추가 비용 없이 처리합니다.
OneRouter는 단일 엔드포인트를 통해 수백 개의 AI 모델에 대한 액세스를 제공하는 통합 API를 제공하며, 자동으로 예비 처리를 수행하고 가장 비용 효율적인 옵션을 선택합니다. 선호하는 SDK나 프레임워크를 사용하여 몇 줄의 코드로 시작해 보세요.
원라우터는 클로드 코드를 지원합니다.
By 앤드류 젱 •



