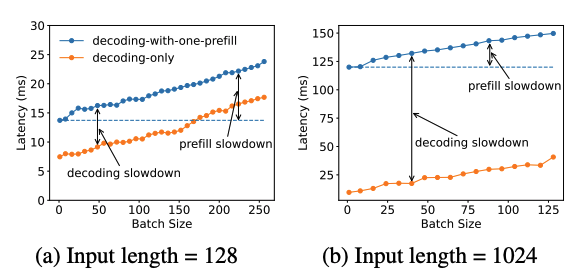
Latency increase by co-locating prefill and decode. Image Source
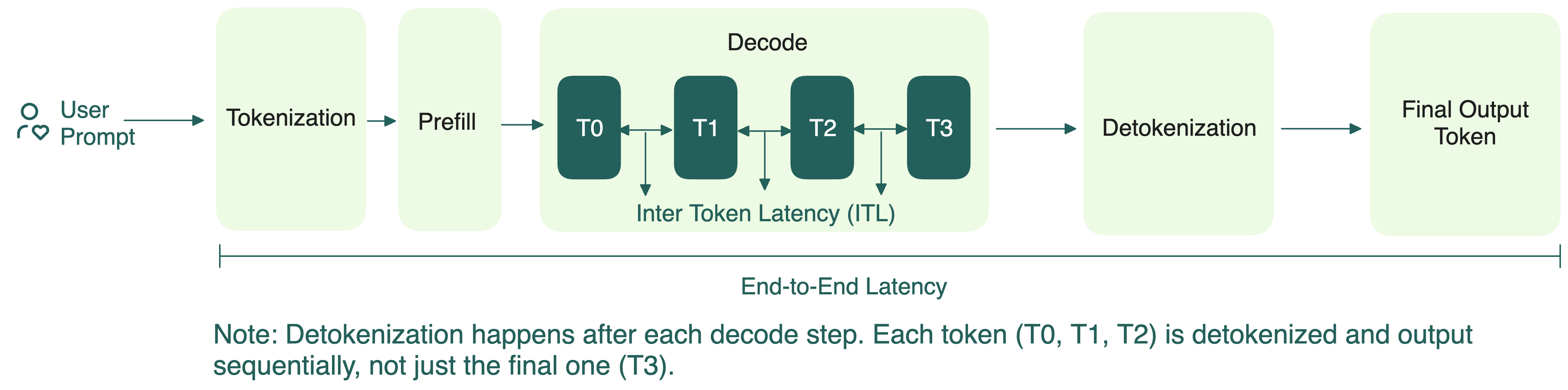 For a long time, the standard way of doing inference was to run these two steps together. On the surface, this might seem straightforward.
In practice, you’ll often have multiple requests arriving at once. Each one has its own prefill and decode needs, but only one phase can run at a time. When the GPU is occupied with compute-heavy prefill tasks, decode tasks must wait, which increases ITL, and vice versa.
Since prefill primarily determines the TTFT and decode impacts ITL, collocating them makes it difficult to optimize both metrics simultaneously.
For a long time, the standard way of doing inference was to run these two steps together. On the surface, this might seem straightforward.
In practice, you’ll often have multiple requests arriving at once. Each one has its own prefill and decode needs, but only one phase can run at a time. When the GPU is occupied with compute-heavy prefill tasks, decode tasks must wait, which increases ITL, and vice versa.
Since prefill primarily determines the TTFT and decode impacts ITL, collocating them makes it difficult to optimize both metrics simultaneously.
Latency increase by co-locating prefill and decode. Image Source